AI知識ベースが20分で完成?Workers AI + VectorizeでRAGを作成する完全ガイド(コード付き)
はじめに
会社のスマートカスタマーサポートを作ろうと思い立ち、RAG のチュートリアルを調べ回りました。しかし、理論ばかりで煙に巻かれるか、「まずはGPUを借りて環境構築を…」といきなりハードルが高いものばかり。正直、私も最初は LangChain とベクトルデータベースの設定だけで2日間格闘し、結局動かなくて頭を抱えました。
その後、Cloudflare が Workers AI + Vectorize + D1 という一連のAIツールを出しているのを見つけました。フルマネージドで、無料枠も太っ腹。試しにノートQ&Aアプリを作ってみたら、ゼロから動くようになるまで20分もかかりませんでした。コードも百行程度です。
この記事では、完全なプロセスをステップバイステップで案内します:
- まず理解する:RAG とは何か(専門用語なし、わかりやすく)
- 実践作成:実際に動作する知識ベースQ&Aアプリを作る(完全なコード付き)
- 最適化テクニック:検索精度向上とコスト削減
- デプロイ:実際に公開して使う
JavaScriptが少しわかり、Cloudflareアカウント(無料)があれば、手順通りに進めるだけで作れます。
RAG って何? 5分でわかる仕組み
テストに例えて理解する RAG
直感的な例え話をしましょう。試験を受ける時、教科書持込不可だと自分の記憶だけが頼りです。忘れてしまったら適当に書くしかありません。しかし「教科書持込可」ならどうでしょう? 不確かな時は本で調べて、正確な答えを書くことができます。
RAG(Retrieval-Augmented Generation、検索拡張生成)とは、AIに「教科書持込試験」の権限を与えることです。
従来のLLMは「持込不可」で、訓練時に見たデータに基づいてしか答えられません。問題点は:
- 訓練データには時効があり、最新情報を知らない
- あなたの会社の内部ドキュメントを見たことがない
- 全ての詳細を記憶できず、適当な嘘をつく(「ハルシネーション」といいます)
RAG のやり方は:まずあなたが用意した知識ベースから関連資料を探し、それをAIに渡して、「これに基づいて答えて」と指示します。これなら、答えは信頼でき、かつ最新情報も反映できます。
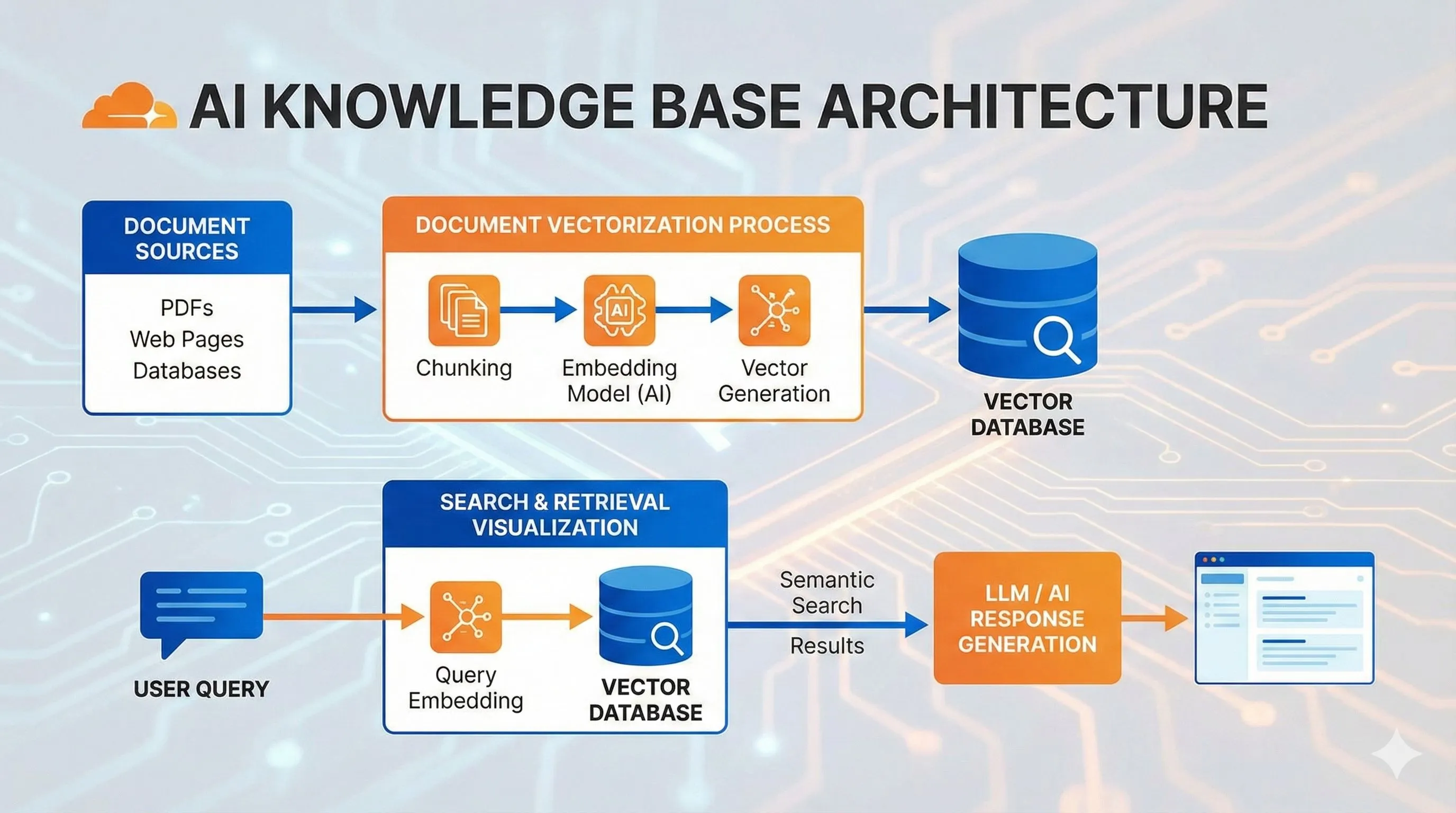
RAG の3つの核心ステップ
プロセス全体はたった3ステップです:
ステップ1:知識をベクトルにして保存
大量のドキュメントがありますよね? RAG は各段落を数列(専門用語で「ベクトル」または「Embedding」)に変換します。この数列は文字の意味を表します。
例えば、「猫は可愛い」と「子猫は萌える」は言葉が違いますが、意味が近いので、ベクトル変換後の数列も近くなります。これらのベクトルは Vectorize のようなベクトルデータベースに保存されます。
ステップ2:ユーザーが質問した時、最も関連する知識を探す
ユーザーが「猫のしつけ方は?」と聞いた時、システムはまずその質問もベクトルに変換し、データベース内で「距離が最も近い」コンテンツを探します。つまり、意味的に最も関連する知識です。
これは「類似性検索」と呼ばれ、数万件のデータから最もマッチする3〜5件を数ミリ秒で見つけ出します。
ステップ3:検索された内容を LLM に渡して回答生成
関連コンテンツが見つかったら、プロンプトに組み込んで AI に送ります:
以下は関連資料です:
[検索結果1]
[検索結果2]
...
ユーザーの質問:猫のしつけ方は?
上記の資料に基づいて回答してください。AI はこれらの「参考資料」を見ることで、正確で根拠のある回答を生成できます。
なぜ Cloudflare フルスタックを選ぶのか?
RAG のソリューションは LangChain や LlamaIndex など市場にたくさんありますが、自分で環境構築したり、ベクトルDBを選んだり、GPUリソースを管理したりと、結構面倒です。
Cloudflare のソリューションの利点は:
Workers AI - Llama 3 や Claude など十数種類のオープンソースモデルを内蔵。API を呼ぶだけで使え、GPU を借りる必要がありません。無料枠には毎日の Neurons(計算単位)が含まれており、個人プロジェクトには十分です。
Vectorize - マネージドベクトルデータベース。Milvus や Pinecone などを自分で立てる必要がありません。インデックス作成、ベクトル挿入、類似検索が数行のコードで済みます。
D1 - Cloudflare の SQLite データベース。元テキストの保存に使います。ベクトルデータベースはベクトルしか保存しないので、具体的なテキスト内容はここから取得します。
フルマネージド - これが最高です。サーバー管理、スケーリング、バックアップなどの雑務を気にする必要がなく、コードを書くことに集中できます。しかも Cloudflare のエッジネットワークなので、世界中どこからでも高速です。
"2025年、CloudflareはAutoRAGを発表。R2にドキュメントをアップロードするだけで、分割・ベクトル化・検索・生成を全自動で行えるようになりました"
2025年、Cloudflare はさらに AutoRAG をリリースし、プロセスを簡素化しました。R2 にドキュメントを上げるだけで後は全自動です。とはいえ、この記事では基礎原理を学ぶために手動での構築方法を解説します。
理論はそのくらいにして、実際に作ってみましょう。
実践ハンズオン - 最初の RAG アプリ構築
ノートQ&Aアプリを作ります。ユーザーがノートを追加でき、質問するとシステムが全ノートから関連内容を探して回答します。
プロジェクト初期化と環境準備
Wrangler(Cloudflare CLIツール)をインストール:
npm install -g wrangler
wrangler login # Cloudflareアカウントにログインプロジェクト作成:
npm create cloudflare@latest rag-notes-app
# "Hello World" worker を選択
# TypeScript を選択
cd rag-notes-appルーティングライブラリ Hono をインストール(ネイティブ Workers API より使いやすい):
npm install honoD1 データベースと Vectorize インデックスを作成:
# 元のノートを保存する D1 データベース作成
wrangler d1 create notes-db
# Vectorize インデックス作成(768次元、bge-base-en-v1.5 モデル用)
wrangler vectorize create notes-index --dimensions=768 --metric=cosineそして wrangler.jsonc(または wrangler.toml)を設定:
{
"name": "rag-notes-app",
"main": "src/index.ts",
"compatibility_date": "2024-01-01",
"node_compat": true,
// AI バインディング
"ai": {
"binding": "AI"
},
// D1 データベースバインディング
"d1_databases": [
{
"binding": "DB",
"database_name": "notes-db",
"database_id": "あなたのデータベースID" // 作成コマンドの出力からコピー
}
],
// Vectorize インデックスバインディング
"vectorize": [
{
"binding": "VECTORIZE",
"index_name": "notes-index"
}
],
// Workflow バインディング(非同期ベクトル化処理用)
"workflows": [
{
"binding": "RAG_WORKFLOW",
"name": "rag-workflow",
"class_name": "RAGWorkflow"
}
]
}データベーステーブルの初期化:
-- schema.sql
CREATE TABLE IF NOT EXISTS notes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);実行してテーブル作成:
wrangler d1 execute notes-db --file=./schema.sql知識ベース登録機能の実装
ここが RAG の核心、ユーザーのノートをベクトルに変換して保存する部分です。
src/workflow.ts を作成(Workflow で非同期タスクを処理):
import { WorkflowEntrypoint, WorkflowStep } from 'cloudflare:workers';
type Env = {
AI: Ai;
DB: D1Database;
VECTORIZE: VectorizeIndex;
};
type Params = {
noteId: number;
text: string;
};
export class RAGWorkflow extends WorkflowEntrypoint<Env, Params> {
async run(event: WorkflowEvent<Params>, step: WorkflowStep) {
const { noteId, text } = event.payload;
// ステップ1:D1レコード作成確認(メインルートで完了済)
// ステップ2:ベクトル生成
const embeddings = await step.do('generate embeddings', async () => {
const response = await this.env.AI.run(
'@cf/baai/bge-base-en-v1.5', // 768次元の Embedding モデル
{ text: [text] }
);
return response.data[0]; // ベクトル配列を返す
});
// ステップ3:Vectorize に挿入
await step.do('insert vector', async () => {
await this.env.VECTORIZE.insert([
{
id: noteId.toString(),
values: embeddings,
metadata: { text } // デバッグ用にテキストも保存
}
]);
});
}
}メインルート src/index.ts(ノート追加処理):
import { Hono } from 'hono';
import { RAGWorkflow } from './workflow';
type Bindings = {
AI: Ai;
DB: D1Database;
VECTORIZE: VectorizeIndex;
RAG_WORKFLOW: Workflow;
};
const app = new Hono<{ Bindings: Bindings }>();
// ノート追加
app.post('/notes', async (c) => {
const { text } = await c.req.json<{ text: string }>();
if (!text?.trim()) {
return c.json({ error: 'Text is required' }, 400);
}
// D1 に挿入
const result = await c.env.DB.prepare(
'INSERT INTO notes (text) VALUES (?) RETURNING id'
).bind(text).first<{ id: number }>();
if (!result) {
return c.json({ error: 'Failed to create note' }, 500);
}
// Workflow をトリガーして非同期ベクトル生成
await c.env.RAG_WORKFLOW.create({
params: { noteId: result.id, text }
});
return c.json({
id: result.id,
message: 'Note created, vectorization in progress'
});
});
export default app;
export { RAGWorkflow };これで、ユーザーが POST リクエストでノートを追加すると:
- テキストは即座に D1 に保存
- バックグラウンド Workflow がゆっくりベクトルを生成し Vectorize に挿入
- ベクトル化に数秒かかっても、ユーザーのリクエストはブロックされません
スマートQ&A機能の実装
ノートを保存できるようになったので、次は検索です。
src/index.ts に追加:
// Q&A検索
app.get('/', async (c) => {
const query = c.req.query('q');
if (!query) {
return c.json({ error: 'Query parameter "q" is required' }, 400);
}
// ステップ1:質問をベクトルに変換
const queryEmbedding = await c.env.AI.run(
'@cf/baai/bge-base-en-v1.5',
{ text: [query] }
);
// ステップ2:Vectorize で最も類似する3つのノートを検索
const matches = await c.env.VECTORIZE.query(
queryEmbedding.data[0],
{ topK: 3, returnMetadata: true }
);
if (matches.count === 0) {
return c.json({ answer: '関連するノートが見つかりませんでした' });
}
// ステップ3:D1 から完全なテキストを取得(必要に応じて)
const noteIds = matches.matches.map(m => m.id);
const notes = await c.env.DB.prepare(
`SELECT text FROM notes WHERE id IN (${noteIds.map(() => '?').join(',')})`
).bind(...noteIds).all();
// ステップ4:Prompt を構築し、LLM を呼び出して回答生成
const context = notes.results.map((n: any) => n.text).join('\n\n---\n\n');
const prompt = `以下は関連するノートの内容です:
${context}
ユーザーの質問:${query}
上記のノート内容に基づいてユーザーの質問に答えてください。ノートに関連情報がない場合は、そう説明してください。`;
const aiResponse = await c.env.AI.run(
'@cf/meta/llama-3-8b-instruct', // または claude-3-5-sonnet-latest
{
messages: [
{ role: 'system', content: 'あなたはスマートノートアシスタントです' },
{ role: 'user', content: prompt }
]
}
);
return c.json({
answer: aiResponse.response,
sources: matches.matches.map(m => ({
id: m.id,
score: m.score,
text: m.metadata?.text
}))
});
});テストしてみましょう:
# ローカル実行
wrangler dev
# ノート追加
curl -X POST http://localhost:8787/notes \
-H "Content-Type: application/json" \
-d '{"text": "Cloudflare Workers AI は Llama 3 と Claude モデルをサポートしています"}'
curl -X POST http://localhost:8787/notes \
-H "Content-Type: application/json" \
-d '{"text": "Vectorize はベクトル検索にコサイン類似度を使用します"}'
# 数秒待って Workflow のベクトル化完了を待つ
# 質問する
curl "http://localhost:8787/?q=Workers%20AI%20はどのモデルを使えますか"すべて正常なら、ノートの内容に基づいた回答が返ってくるはずです。
削除と更新機能
ノートを削除する時は、D1 と Vectorize の両方から削除するのを忘れずに:
app.delete('/notes/:id', async (c) => {
const id = c.req.param('id');
// D1 から削除
await c.env.DB.prepare('DELETE FROM notes WHERE id = ?').bind(id).run();
// Vectorize から削除
await c.env.VECTORIZE.deleteByIds([id]);
return c.json({ message: 'Note deleted' });
});更新の場合は、削除して再追加(ベクトル再生成)するのが一番簡単です。
完全なコードは Cloudflare 公式サンプル も参考にしてください。
上級最適化 - RAG をより賢くする
基本機能は動きましたが、実際のプロジェクトで使うには細部の最適化が必要です。
テキストチャンキング(Chunking)戦略
今はノート全体を1つの単位として保存しています。もしノートが非常に長い(例えば技術ドキュメント)場合、問題が起きます:
- 検索時、ドキュメント全体の類似度が低くなる(一部の段落だけが関連しているため)
- Prompt が長すぎて LLM のコンテキストウィンドウ制限を超える
より良い方法は 長文を小さな塊(チャンク)に切る ことです。各チャンクを個別にベクトル化します。
簡単な分割方法:
function splitText(text: string, chunkSize: number = 500, overlap: number = 50): string[] {
const chunks: string[] = [];
let start = 0;
while (start < text.length) {
const end = Math.min(start + chunkSize, text.length);
chunks.push(text.slice(start, end));
start = end - overlap; // 文が途切れないよう少し重ねる
}
return chunks;
}よりスマートな方法は段落や意味で分割することですが(LangChain の RecursiveCharacterTextSplitter など)、多くのシーンでは固定長+オーバーラップで十分です。
Workflow を修正し、各チャンクにユニーク ID を割り当てます:
const chunks = splitText(text);
for (let i = 0; i < chunks.length; i++) {
const chunkId = `${noteId}-${i}`;
const embeddings = await this.env.AI.run('@cf/baai/bge-base-en-v1.5', {
text: [chunks[i]]
});
await this.env.VECTORIZE.insert([{
id: chunkId,
values: embeddings.data[0],
metadata: { noteId, chunkIndex: i, text: chunks[i] }
}]);
}検索精度の向上
topK と類似度閾値の調整
デフォルトのトップ3では足りないか、多すぎるかもしれません。5件取得して、類似度が低すぎるものをフィルタリングしてみましょう:
const matches = await c.env.VECTORIZE.query(queryEmbedding.data[0], {
topK: 5,
returnMetadata: true
});
// 類似度 > 0.7 の結果のみ保持
const relevantMatches = matches.matches.filter(m => m.score > 0.7);類似度スコアは 0-1(コサイン類似度)、0.7以上なら一般的に関連性が高いです。
Prompt 最適化
ただ検索結果を AI に投げるだけでなく、どう使うかを指示します:
const prompt = `あなたはスマートノートアシスタントです。以下はノートライブラリから検索された関連コンテンツです(関連順):
${context}
上記のコンテンツのみに基づいて、ユーザーの質問に厳密に答えてください。もし回答に必要な情報がない場合は、「ノートに関連情報が見つかりませんでした」と明記し、適当な答えを作らないでください。
ユーザーの質問:${query}`;ポイント:
- これが検索された資料であると明言する
- これだけに基づいて回答せよと指示する
- 「わからない」と言うことを許可する
これで AI のでっち上げが減ります。
コスト管理とレート制限
Workers AI の無料枠には毎日の Neurons 制限があります(具体的な数値は Pricing ページ を確認)。
使用量監視:
Cloudflare Dashboard → Workers AI で毎日の消費量が見れます。モデルによって消費量が異なります(Embedding は安く、LLM 生成は高い)。
ダウングレード戦略:
超過が心配なら:
- ユーザーごとのリクエスト頻度を制限(KV や Durable Objects でカウント)
- 制限を超えたら小さいモデルを使うか、キャッシュ結果を返す
- 重要でないリクエストは LLM を呼ばず、検索された原文を直接返す
// 簡単なレート制限例
const userKey = c.req.header('X-User-ID') || 'anonymous';
const requestCount = await c.env.KV.get(`rate:${userKey}`) || 0;
if (requestCount > 100) {
return c.json({ error: 'Rate limit exceeded' }, 429);
}
await c.env.KV.put(`rate:${userKey}`, requestCount + 1, { expirationTtl: 86400 });より強力なモデルへの切り替え
Llama 3 8B も優秀ですが、より高い理解力が必要なら Claude を試してください:
// Dashboard で Anthropic API key のバインディングが必要
const aiResponse = await c.env.AI.run('claude-3-5-sonnet-latest', {
messages: [
{ role: 'system', content: 'あなたはスマートノートアシスタントです' },
{ role: 'user', content: prompt }
]
});Claude の理解力と出力品質は確かに上ですが、Neurons 消費も増えます。実際のニーズに合わせて選びましょう。
私の経験:
- 単純なQ&A:Llama 3 で十分
- 推論、要約が必要:Claude が明らかに良い
- 予算制限:まず Llama でテストし、必要ならアップグレード
デプロイと実際の応用シーン
デプロイフロー
ローカルテストで問題なければ、デプロイは超簡単です:
wrangler deployこれ一行で、Cloudflare は自動的に:
- コードをパッケージング
- 全世界のエッジノードにデプロイ
.workers.devドメインを生成
以下のような出力が出ます:
Published rag-notes-app
https://rag-notes-app.your-account.workers.devこれがあなたの API アドレスです。
カスタムドメインのバインド(オプション):
Cloudflare でドメイン管理しているならバインドできます:
wrangler domains add api.yourdomain.comまたは Dashboard → Workers & Pages → あなたの Worker → Settings → Domains から追加。
環境変数と Secrets:
Anthropic API key やその他機密情報を使う場合:
wrangler secret put ANTHROPIC_API_KEY
# キーを入力コード内での使用:
const apiKey = c.env.ANTHROPIC_API_KEY;リアルな応用シーン
この RAG アーキテクチャでできることは多いです。いくつか例を挙げます:
1. 企業知識ベースQ&A
シーン:会社に数百ページの従業員マニュアル、技術文書、FAQがあり、新人が資料を探すのが大変。
やり方:
- 全ドキュメントをアップロード、章ごとにチャンク化して Vectorize に保存
- 簡単な Web 画面か、Slack/Teams ボットを作る
- 従業員が「経費精算のフローは?」と聞けば、システムが関連章を検索して回答
メリット:24時間即答、ドキュメントをめくるより断然速い。
2. スマートカスタマーサポート
シーン:ECサイトに大量の商品情報とアフターサービスポリシーがあり、サポートが同じ質問に答え続けている。
やり方:
- よくある質問、商品説明、返品ポリシーを保存
- ユーザーの問い合わせにまず RAG システムが回答
- 答えられない場合のみ有人対応へ
効果:ある開発者はこの構成でサポートの負荷を 60% 以上削減しました。
3. 個人ノートアシスタント
シーン:Notion や Obsidian に何年もノートを貯めたが、特定の知識をすぐに見つけられない。
やり方:
- 定期的にノートをエクスポートし、API 経由で RAG システムに追加
- 必要な時に「前回見た TypeScript のテクニックなんだっけ」と聞く
- システムが関連ノート断片を検索
私自身も似たツールを使っていますが、資料探しの効率が本当に上がりました。
4. “Chat with PDF” ツール
シーン:ユーザーが PDF(論文、契約書、レポート)をアップロードし、情報を素早く抽出したい。
やり方(Rohit Patil の事例参考):
- ユーザーが PDF を R2 にアップロード
- Worker が PDF を読み、テキスト抽出、チャンク化、ベクトル化
- ユーザーが「この契約書の支払い条項は?」と聞く
このシーンは特に実用的で、法律やコンサル業界で需要があります。
よくあるトラブルシューティング
問題1:ベクトル次元の不一致
エラー:dimension mismatch: expected 768, got 512
原因:Vectorize インデックス作成時の次元設定(768)とモデル出力次元が一致していない。
解決:インデックス次元とモデルを合わせる。bge-base-en-v1.5 は 768 次元なので、モデルを間違えないように。
問題2:D1 と Vectorize のデータ不整合
現象:クエリで返ってきた note ID が D1 に存在しない。
原因:D1 レコード削除時に Vectorize 側を消し忘れた、または Workflow が失敗した。
解決:削除操作をトランザクションにするか、Workflow で両方確実に削除する。
問題3:Workflow タイムアウト
エラー:workflow execution timeout
原因:大量のテキストをベクトル化する際、Workflow の制限時間を超えた。
解決:大ドキュメントは複数の Workflow タスクに分割するか、バッチ処理する。
// バッチ処理
const batchSize = 10;
for (let i = 0; i < chunks.length; i += batchSize) {
const batch = chunks.slice(i, i + batchSize);
await c.env.RAG_WORKFLOW.create({
params: { noteId, chunks: batch, offset: i }
});
}結論
長くなりましたが、まとめると:
- RAG の原理を理解:検索拡張生成、AI に「カンニング」させることで正確さを上げる
- 動くアプリを作成:ノートQ&Aシステムを、環境構築からコード実装まで一通り完了
- 最適化テクニック学習:テキストチャンキング、検索調整、コスト管理で実用性を向上
- 実用シーン検討:企業知識ベース、スマートサポート、個人アシスタント、PDF チャットなど
Cloudflare のこのセットの最大の利点は敷居の低さです。GPU もデータベースもサーバーも自前で用意する必要がなく、無料枠で個人プロジェクトは十分回ります。本番環境でも、有料プランは自前運用より遥かに安いです。
次はあなたが:
- すぐに手を動かす:公式サンプルコード をクローンし、
wrangler devで動かしてみる(5分で効果が見れます) - リアルデータを入れる:自分のノート、ドキュメント、FAQ を入れて、検索品質を試す
- フロントエンドを作る:React/Vue で簡単なチャット画面を作るか、Cloudflare Pages でデプロイする
- さらに探索:マルチモーダル RAG(画像、表との組み合わせ)、GraphRAG(知識グラフ拡張)など高度な遊び方を試す
RAG は今の AI アプリで最も実用的なアーキテクチャの一つです。これをマスターすれば、面白いものがたくさん作れます。試してみると、Cloudflare フルスタックが多くの実問題を解決してくれることがわかるでしょう。
何かあれば、Cloudflare Discord や Community フォーラム で聞いてみてください。コミュニティは活発です。
常见问题
RAGと従来の検索エンジンの違いは?
• キーワード一致に基づいてドキュメントリンクを返す
RAG:
• 意味理解に基づいて関連コンテンツを検索し、自然言語で回答を生成
• 「猫は可愛い」と「子猫は萌える」が似た意味だと理解できる
• 従来の検索は同じキーワードしかマッチしない
• RAGは直接答えを出すので、ユーザーが複数のドキュメントを読む必要がない
Cloudflare無料版はどれくらいの知識ベースをサポートできますか?
• D1無料版は10GBストレージ
• Vectorize無料版は500万ベクトル(約5GBのテキストコンテンツ)
個人プロジェクトや中小企業の知識ベースには十分すぎます。
より大容量が必要な場合は、有料版へのアップグレードや、複数インデックスによるシャーディングが可能です。
RAGの検索精度を上げるには?
1) 適切なチャンキング(Chunking):
• サイズ 500-1000文字
• オーバーラップ 50-100文字
2) パラメータ調整:
• topKパラメータ(通常3-5件)
• 類似度閾値(>0.7)
3) Prompt 最適化:AIに検索内容に基づいて回答するよう明確に指示
4) より良いEmbeddingモデル利用(OpenAIのtext-embedding-3など)
5) 高頻度の質問にはFAQキャッシュを作成
RAGアプリのコストを抑えるには?
1) Workers AI の無料枠(毎日固定 Neurons)を活用
2) ユーザーリクエスト頻度を制限(KVカウンター)
3) 高頻度質問の回答をキャッシュ
4) 単純な質問には Llama 3、複雑なタスクには Claude と使い分け
5) 1日の消費量を監視し、制限に近づいたら LLM を呼ばず検索結果のみ返すようダウングレード
RAGはどのような実用シーンに適していますか?
1) 企業知識ベースQ&A(従業員マニュアル、技術文書、ポリシー照会)
2) スマートカスタマーサポート(商品相談、アフターサービス、FAQ)
3) 個人ノートアシスタント(長年蓄積したノートの高速検索)
4) ドキュメントQ&Aツール(PDF/Wordをアップロードして情報抽出)
既存の知識に基づいて質問に答える必要があるあらゆるシーンに適しています。
7 min read · 公開日: 2025年12月1日 · 更新日: 2026年3月3日
関連記事
プログラマー向けAIツール実践:OpenClaw + Claude Codeによる24時間自動バグ修正

プログラマー向けAIツール実践:OpenClaw + Claude Codeによる24時間自動バグ修正
第二の脳を構築する:OpenClawとObsidian/Notionのディープ・メモリー同期実践

第二の脳を構築する:OpenClawとObsidian/Notionのディープ・メモリー同期実践
警告!ClawHubスキルライブラリで800以上の悪意あるプラグインを発見。あなたのAPI Keyは本当に安全ですか?

コメント
GitHubアカウントでログインしてコメントできます