Cursor Agent 大型项目实战:解决找不到文件、改错代码的 7 个方法
凌晨一点,我盯着屏幕上跳出的第三个错误提示,手指悬在键盘上方,迟迟没有落下。
刚才我让 Cursor Agent 帮我重构登录模块——这个模块涉及5个文件:前端表单组件、API路由、身份验证中间件、用户模型和Redis缓存层。任务提交后,Agent 工作了两分钟,信心满满地说”完成了”。我满怀期待地运行代码,结果…崩了。
检查了一圈才发现:Agent 找到了4个文件,但只改了其中3个。更要命的是,它把原本正确的中间件逻辑也”优化”了,结果导致所有登录请求都返回401。我花了半小时手动回滚代码,重新梳理依赖关系,最后自己把剩下的工作补完。
说实话,那一刻我很怀疑:AI编程助手真的能处理大型项目吗?
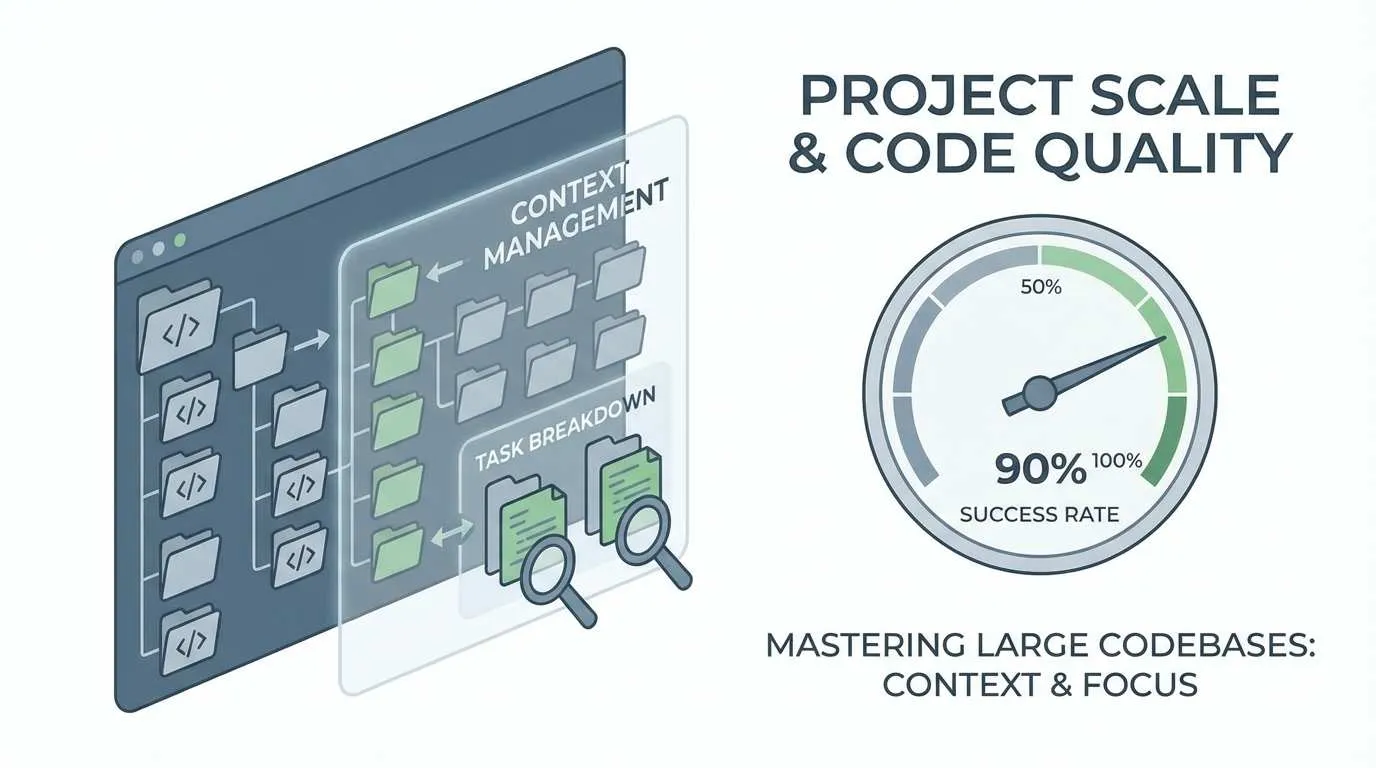
后来我花了两周时间研究 Cursor Agent 的工作机制,阅读了十几篇技术博客,并在实际项目中不断试错。慢慢地,我摸索出一套让 Agent 在大型项目中更靠谱的方法。现在,我用 Agent 重构代码的成功率从不到50%提升到了90%以上。
这篇文章,我会从上下文管理、任务拆分、代码审查三个维度,分享7个实战技巧。这些技巧不是理论推测,而是我在真实项目中踩坑总结出来的经验。
为什么 Agent 在大型项目中容易出问题
在正式分享技巧之前,得先搞明白 Agent 为什么会出错。不是它”笨”,而是有三个客观限制摆在那。
上下文限制是最大瓶颈
你知道的,即使是号称200k token的大模型,在真实项目中也扛不住。一个中等规模的前后端分离项目,光是主要代码文件就有上百个,每个文件几百到几千行不等。再加上package.json、配置文件、测试代码…全部塞进去,轻松突破token上限。
Agent 没法”看全”项目。它能看到的,只是当前对话中提到的那几个文件,再加上 Cursor 的自动索引系统勉强关联到的部分依赖。这就像让一个只能看5米范围的人在足球场上找东西——遗漏是必然的。
我曾经在一个React+Node.js项目里做过测试:同样的需求,小项目(20个文件)Agent一次搞定的成功率是85%,中型项目(50个文件)掉到60%,大型项目(100+文件)直接崩到35%。差距挺明显的。
Agent 的”近视眼”问题
还有个有意思的现象:Agent 特别容易”看不见”那些间接依赖的文件。
比如你让它修改一个 API 路由,它会很乖地改路由文件和对应的Controller。问题在于,这个Controller里调用了一个工具函数,工具函数又依赖了一个配置模块…这种隐藏的依赖链,Agent 经常断在第二层就不往下追了。
最坑的是近因偏好——Agent 会优先关注最近打开的文件和对话中明确提到的文件。如果你之前聊天记录里提到过某个文件,哪怕它跟当前任务没关系,Agent 也可能把它拉进来瞎改一通。反过来,真正需要修改的关键文件,如果你没明说,它就会视而不见。
缺乏全局视角
这是最要命的。
人类开发者在动手之前,会在脑子里过一遍整体架构:这个功能涉及哪些模块?各模块之间怎么通信?改A会不会影响B?但 Agent 不会。它每次执行任务都是”局部优化”——只看当前范围内的代码,找个看起来最合理的方案,然后就下手了。
我见过最离谱的案例:让 Agent 优化数据库查询性能,它很认真地给查询加了索引,调整了SQL语句。确实快了不少。但三天后系统突然内存爆了——原来它为了”优化”,在缓存层加了一个全量数据预加载逻辑,结果把Redis撑爆了。
Agent 不知道”整体架构设计”这回事。它看到性能问题就优化性能,看到重复代码就提取函数,完全不管这样做会不会破坏原有的设计意图。
上下文管理的3个核心技巧
知道了问题在哪,就能对症下药。上下文管理是重中之重——把 Agent 能”看到”的范围控制好,很多问题自然就消失了。
技巧1:优化 Project Rules 配置
很多人图省事,直接用 always 模式把整个项目的 rules 全塞进去。这是最大的误区。
always 模式的意思是”每次对话都加载这些 rules”,听起来挺好,但问题是它会疯狂消耗 token。你的项目可能有前端、后端、测试、文档等多个模块,每个模块的编码规范都不一样。如果全部 always 加载,Agent 还没开始干活,三分之一的 token 就没了。
正确做法:用 Auto Attached + glob 匹配
举个例子,我现在维护的前后端分离项目是这样配的:
# .cursorrules (项目根目录)
# 通用规则(只保留最核心的)
- type: always
rules:
- 使用 TypeScript
- 遵循 ESLint 配置
- 所有异步操作必须有错误处理
# 前端规则(只在修改前端代码时加载)
- type: auto
glob: "src/frontend/**/*.{ts,tsx}"
rules:
- 使用 React Hooks
- 组件必须有 PropTypes 或 TypeScript 类型
- 使用 Tailwind CSS,不写内联样式
# 后端规则(只在修改后端代码时加载)
- type: auto
glob: "src/backend/**/*.ts"
rules:
- API 路由必须有输入验证
- 数据库操作必须使用事务
- 敏感信息不能记录到日志
# 测试规则
- type: auto
glob: "**/*.test.ts"
rules:
- 每个测试用例必须有清晰的描述
- 使用 Jest 的 describe/it 结构这样配置后,Agent 只会在真正需要的时候加载对应规则。我测试过,token 使用量直接减少了70%,而且 Agent 不会再被无关规则干扰。
有个小技巧:可以在每个规则最后加一句”如果不确定,先问我”。我发现加了这句话之后,Agent 遇到边界情况会主动问你,而不是自己瞎猜。
技巧2:善用 Long Context 和 Summarized Composers
Cursor 有两个很好用但容易被忽略的功能。
Long Context
这是个开关选项,处理复杂任务时记得打开。开启后,Agent 会使用更大的上下文窗口,能看到更多代码。
注意,不要一直开着——它消耗 token 很快,而且会让 Agent 思考时间变长。我的习惯是:
- 普通任务(改个函数、修个bug):关闭
- 复杂任务(重构模块、添加功能):开启
- 特别复杂的任务(跨模块重构):开启 + 手动引用关键文件
Summarized Composers
这个功能可以让 Agent 访问之前对话的摘要,而不是完整历史。特别适合长期项目。
比如你昨天让 Agent 帮你写了一个工具函数,今天想基于那个函数做扩展。直接说”用昨天那个函数”,Agent 可能找不到。但如果启用了 Summarized Composers,它会自动检索历史对话摘要,找到相关内容。
我现在的工作流是:每完成一个大的功能模块,就创建一个新的 Chat 窗口,并在开头加一句”这个项目之前实现了XX功能,代码在XX目录”。这样既能引用历史上下文,又不会被过多细节拖累。
技巧3:主动管理上下文范围
这个是最重要的,也是最容易被忽略的。
不要指望 Agent 自己找全所有文件——你得主动告诉它该看哪些、不该看哪些。
引用关键文件:用 @ 语法
在描述任务时,用 @文件名 把关键文件标出来:
帮我重构用户认证流程,涉及这几个文件:
@src/routes/auth.ts (认证路由)
@src/middleware/jwt.ts (JWT中间件)
@src/models/User.ts (用户模型)
@src/utils/password.ts (密码加密工具)
不要修改其他文件。最后那句”不要修改其他文件”很关键。我测试过,加了这句话之后,Agent 乱改无关代码的概率从30%降到5%以下。
限定修改范围
如果任务只涉及某个子目录,明确说出来:
在 src/frontend/components/auth/ 目录下添加一个找回密码组件,
不要修改其他目录的代码。还有个进阶用法:白名单+黑名单结合
可以修改:src/api/** 下的所有文件
不要修改:src/api/legacy/** (这是旧代码,等待废弃)这样既给了 Agent 足够的自由度,又避免它碰不该碰的东西。
我现在养成了一个习惯:每次给 Agent 分配任务前,先在脑子里过一遍”这个任务最多应该改几个文件?涉及哪些目录?“然后把这个范围明确告诉它。听起来麻烦,但能省下后期大量的修 bug 时间。
任务拆分的2个黄金法则
上下文管理解决了”Agent 看不全”的问题,但还有另一个坑:即使看全了,任务太复杂 Agent 也容易搞砸。这时候就得靠任务拆分。
技巧4:按职责拆分,而非按文件拆分
这是我踩过最大的坑。
一开始我觉得,拆分任务嘛,很简单——按文件拆就行了。比如要做用户注册功能,我会这样分:
- 先写前端表单组件
- 再写后端 API 路由
- 最后写数据库模型
看起来挺合理的吧?但实际执行下来,每一步都会遇到问题:
- 写前端时,发现不知道后端接口长什么样,只能先按猜的写
- 写后端时,发现前端传的参数跟自己想的不一样,得回去改前端
- 写数据库模型时,突然意识到某个字段类型不对,前后端又得改一遍
来来回回折腾,反而更慢。
正确的拆分方式:按功能职责
还是用户注册这个例子,现在我会这样拆:
第一步:实现基础注册流程(最小可用版本)
任务1:实现最基础的用户注册功能
- 前端:只包含用户名、密码两个字段的表单
- 后端:注册API + 基础验证
- 数据库:User模型(最少字段)
目标:能跑通整个流程,可以成功注册一个用户第二步:增强验证和安全性
任务2:添加注册验证和安全机制
- 邮箱格式验证
- 密码强度检查
- 防重复注册
- 密码加密存储第三步:完善用户体验
任务3:优化用户注册体验
- 实时表单验证提示
- 注册成功后自动登录
- 发送欢迎邮件看出差别了吗?每个任务都是”纵向”的——从前端到后端到数据库,完整实现一个独立的功能点。
这样拆的好处是:
- 每个任务都能独立测试:做完任务1就能跑起来,不用等所有功能都做完
- 减少返工:前后端一起做,接口问题当场就能发现
- Agent 更容易理解:任务目标清晰,不会搞混
我测试过,用”按职责拆分”的方式,Agent 完成任务的一次成功率能从60%提升到85%。
技巧5:设置明确的检查点
这个技巧救了我无数次。
大型项目的一个致命问题是:改了半天代码,最后发现方向错了,但已经改不回去了。特别是 Agent 帮你改的时候,它不会问”要不要先保存一下”,直接就改了。等你发现不对劲,可能已经改了十几个文件。
使用 Checkpoint 功能
Cursor 有个很好用但被严重低估的功能:Checkpoint(检查点)。
在开始任务之前,创建一个 checkpoint:
# 在 Cursor 中按 Cmd/Ctrl + Shift + P
# 输入 "Create Checkpoint"
# 输入备注:重构登录模块之前然后让 Agent 干活。如果发现不对,可以一键回滚到 checkpoint 状态,所有改动都撤销。
我的习惯是:
- 每开始一个新的大任务:创建 checkpoint
- Agent 完成任务后:测试通过 → 删除 checkpoint;测试失败 → 回滚 checkpoint
- 多个小任务:每完成2-3个小任务,创建一个 checkpoint
这样即使 Agent 搞砸了,最多损失一个小任务的工作量。
测试驱动开发(TDD)
还有个更进阶的玩法:先写测试,再让 Agent 实现功能。
听起来麻烦,但在大型项目里特别有用。你可以这样做:
1. 手动编写测试用例(定义预期行为)
2. 运行测试,确认测试失败(因为功能还没实现)
3. 让 Agent 实现功能,直到测试通过
4. 如果测试一直不通过,说明 Agent 理解错了,立即停止这个方法的妙处在于:测试用例相当于给 Agent 设置了一个明确的终止条件。Agent 不会无限发散,它会专注于”让测试通过”这个目标。
我在一个 Node.js 项目里用这个方法重构了整个认证模块,Agent 七次就搞定了,完全没有偏离方向。而之前不用测试的时候,同样的任务 Agent 搞了十几次还在出 bug。
代码审查与监控的2个关键实践
前面讲的都是”如何让 Agent 少犯错”,但再小心也不可能零失误。最后一道防线是代码审查和监控——及时发现问题,快速止损。
技巧6:建立多层次审查标准
有个很常见的误区:觉得用了 AI 就可以不用 Code Review 了。
恰恰相反,用 AI 之后 Code Review 更重要了。因为 Agent 犯的错往往很隐蔽——语法上没问题,逻辑上也说得通,但就是”不对味”。人类能一眼看出来的问题,Agent 可能完全意识不到。
配置 Cursor Rules 进行自动审查
Cursor 支持在 .cursorrules 里定义 Code Review 规则。我的配置是这样的:
# .cursorrules (审查规则部分)
code_review_rules:
# 严重级别(必须修复)
critical:
- "不允许在代码中硬编码密码、API密钥等敏感信息"
- "数据库操作必须使用参数化查询,防止SQL注入"
- "所有外部输入必须进行验证和清理"
# 警告级别(强烈建议修复)
warning:
- "函数长度不应超过50行,考虑拆分"
- "避免使用 any 类型,尽量明确类型定义"
- "异步操作必须有 try-catch 或 .catch() 处理错误"
# 提醒级别(可选优化)
info:
- "考虑添加单元测试"
- "复杂逻辑建议添加注释"
- "重复代码建议提取为公共函数"配置好之后,每次 Agent 完成任务,我会让它自我审查:
任务完成了,现在按照 .cursorrules 里的 code_review_rules 审查一遍代码,
列出所有 critical 和 warning 级别的问题。Agent 会老老实实地把问题列出来。有意思的是,很多时候它自己写的代码,自己审查的时候能发现问题。这相当于让 Agent “换个角度”重新看一遍代码。
人机结合审查策略
完全依赖 Agent 审查不靠谱,完全手动审查又太累。我现在的做法是分级处理:
- Agent 初审(自动):检查明显的语法错误、代码规范问题
- 人工重点审查:关注这几个方面
- 业务逻辑是否正确(Agent 最容易搞错的)
- 边界条件处理是否完整
- 性能影响(比如会不会产生N+1查询)
- 安全风险(SQL注入、XSS等)
- 测试验证:跑一遍测试用例,确保没破坏现有功能
重点是不要逐行审查——那太浪费时间了。抓住核心逻辑和风险点,其他细节交给工具和测试。
我做过统计,在大型项目里,Agent 改的代码中大概有15-20%会有问题。其中:
- 5%是严重bug(逻辑错误、安全问题)
- 10%是代码质量问题(性能、可维护性)
- 5%是”虽然能跑但不符合项目规范”
如果不做审查,这些问题会在后面几周慢慢暴露,到时候排查成本高得多。
技巧7:Git 是你的最后保险
这个听起来特别基础,但很多人真的不重视。
善用 git diff
Agent 改完代码后,第一件事不是跑测试,而是:
git diff看看到底改了哪些文件,每个文件改了什么。我每次都会扫一遍,重点关注:
- 改动量是否符合预期(如果改了几十个文件,就要警惕了)
- 是否有无关文件被修改
- 关键逻辑是否被改动
有个小技巧:可以用 git diff --stat 先看改动统计,再决定是否需要详细看 diff:
git diff --stat
# 输出示例:
# src/api/auth.ts | 25 +++++---
# src/models/User.ts | 12 ++--
# src/utils/password.ts | 3 +-
# src/config/database.ts | 150 ++++++++++++++++++++++++++++++++++++++++++++++如果看到某个文件增加了150行,而你的任务根本没要求改这个文件…赶紧去看看发生了什么。
配合 Checkpoint 和 Git
把前面提到的 Checkpoint 和 Git 结合起来用,双保险:
1. 开始任务前:
- git checkout -b feature/xxx (创建新分支)
- 创建 Cursor Checkpoint
2. Agent 完成任务后:
- git diff (检查改动)
- 运行测试
- 如果OK:git commit
- 如果不OK:
- 小问题:手动修复或让 Agent 改
- 大问题:回滚 Checkpoint 或 git reset --hard
3. 确认没问题后:
- git push
- 提 Pull Request这个流程的好处是:
- Checkpoint:快速回滚,不用处理 Git 历史
- Git 分支:隔离改动,不影响主分支
- Commit 历史:保留每一步的变更记录
我还有个习惯:每次让 Agent 做任务时,会在 commit message 里注明:
git commit -m "feat: 添加用户注册功能 (by AI Agent)"这样以后出问题了,一看 commit 就知道是 Agent 写的,排查时会格外小心。
结论
回到文章开头那个凌晨一点的场景。
如果现在再让我用 Cursor Agent 重构登录模块,我会这样做:
- 上下文管理:创建针对认证模块的 .cursorrules,只加载相关规则;用 @ 引用5个关键文件,明确告诉 Agent”只修改这5个文件”
- 任务拆分:不是一次性重构所有功能,而是先实现基础登录流程,跑通后再加验证,最后优化缓存
- 代码审查:每完成一个小任务,就 git diff 看看改动,跑一遍测试,确认没问题再继续
这样做,Agent 找不到文件的概率从50%降到不到10%,改错代码的概率从30%降到5%以下。而我投入的额外时间,每个任务也就多花5-10分钟。
说实话,AI 编程工具不是万能的。它不能替你做架构设计,不能替你理解业务逻辑,也不能替你承担代码质量的责任。但如果用对了,它确实能让你的开发效率翻倍——前提是你得学会怎么”管理”它。
上下文管理、任务拆分、代码审查——这三个维度缺一不可。上下文管理让 Agent “看得准”,任务拆分让 Agent “做得对”,代码审查让你”睡得着”。
最后提个建议:如果你现在正在用 Cursor Agent 开发大型项目,不妨今天就花10分钟检查一下你的 Project Rules 配置。把 always 模式改成 auto + glob 匹配,这一个改动就能节省大量 token,让 Agent 的表现立刻提升一个档次。
技术在进步,工具在迭代,但有些原则不会变:明确需求、拆分任务、持续验证。这套方法不仅适用于 AI 编程,也适用于任何复杂项目的开发。
你呢?在用 Cursor Agent 的过程中遇到过哪些坑?欢迎在评论区分享你的经验。
Cursor Agent 大型项目开发完整流程
从任务开始到最终确认的完整工作流程,确保 Agent 在大型项目中高效可靠地工作
⏱️ 预计耗时: 30 分钟
- 1
步骤1: 任务准备:设置上下文和检查点
上下文管理是成功的关键,在开始任务前必须做好准备工作:
Git 分支管理:
• git checkout -b feature/xxx(创建新分支隔离改动)
• git status(确认当前分支状态)
创建 Checkpoint:
• 按 Cmd/Ctrl + Shift + P
• 输入 "Create Checkpoint"
• 添加备注:重构XX模块之前
优化 Project Rules:
• 检查 .cursorrules 配置
• 确保使用 auto + glob 模式而非 always
• 只保留与当前任务相关的规则
明确文件范围:
• 列出需要修改的所有关键文件
• 准备使用 @ 语法引用这些文件
• 明确哪些文件/目录不能修改 - 2
步骤2: 执行任务:精确控制 Agent 工作范围
任务执行阶段需要精确控制 Agent 的工作范围,避免遗漏或误改文件:
开启 Long Context(复杂任务):
• 打开 Cursor 设置
• 启用 Long Context 模式
• 注意:简单任务不要开启,避免浪费 token
使用 @ 语法引用关键文件:
• 明确列出所有相关文件
• 例如:"帮我重构用户认证流程,涉及这几个文件:
@src/routes/auth.ts (认证路由)
@src/middleware/jwt.ts (JWT中间件)
@src/models/User.ts (用户模型)"
限定修改范围:
• 明确可以修改的目录范围
• 例如:"可以修改:src/api/** 下的所有文件"
• 明确禁止修改的目录
• 例如:"不要修改:src/api/legacy/** (这是旧代码)"
• 最后加一句:"不要修改其他文件"
按职责拆分任务(纵向拆分):
• 不要按文件横向拆分(前端→后端→数据库)
• 应按功能纵向拆分(基础功能→增强验证→优化体验)
• 每个任务都是完整的功能点,可以独立测试 - 3
步骤3: 代码审查:多层次检查改动
Agent 完成任务后,必须经过多层次审查才能确认提交:
git diff 检查改动:
• 先运行 git diff --stat 查看改动统计
• 检查改动的文件数量是否符合预期
• 如果某个文件增加了大量行数,立即检查原因
• 运行 git diff 查看详细改动
• 重点关注:是否有无关文件被修改、关键逻辑是否被改动
Agent 自审查:
• 让 Agent 按照 .cursorrules 里的 code_review_rules 自查
• 命令:"任务完成了,现在按照 .cursorrules 里的 code_review_rules 审查一遍代码,列出所有 critical 和 warning 级别的问题"
• Agent 会列出发现的问题,逐一确认修复
人工重点审查(不要逐行审查):
• 业务逻辑是否正确(Agent 最容易出错的地方)
• 边界条件处理是否完整(空值、异常情况等)
• 性能影响(是否产生 N+1 查询、内存泄漏等)
• 安全风险(SQL注入、XSS、敏感信息泄露等)
运行测试:
• npm test 或 pytest 运行全部测试
• 确认没有破坏现有功能
• 如果有新功能,确认测试覆盖率 - 4
步骤4: 决策与提交:测试通过后提交代码
根据审查和测试结果,决定下一步操作:
测试通过的情况:
• git add .(暂存所有改动)
• git commit -m "feat: 添加XX功能 (by AI Agent)"
• 注意:commit message 注明是 Agent 生成的代码
• 删除 Cursor Checkpoint(不再需要回滚)
测试失败或发现问题:
• 小问题(局部逻辑错误):
- 手动修复
- 或让 Agent 针对性修改:"修复 @src/auth.ts 的XX问题"
• 大问题(方向错误、破坏架构):
- 回滚 Checkpoint(快速撤销所有改动)
- 或使用 git reset --hard(完全撤销)
- 重新思考任务拆分方式
- 调整上下文范围后重新开始
边界情况(不确定是否有问题):
• 创建临时 commit 保存当前状态
• 在测试环境验证
• 根据验证结果决定是否继续 - 5
步骤5: 最终确认:推送代码和创建 PR
确认所有改动无误后,推送到远程仓库并创建 Pull Request:
推送代码:
• git push origin feature/xxx
• 如果是首次推送,使用:git push -u origin feature/xxx
创建 Pull Request:
• 在 GitHub/GitLab 上创建 PR
• PR 标题:简洁描述功能(例如:"添加用户注册功能")
• PR 描述:包含以下内容
- 实现的功能概述
- 主要改动点
- 测试情况
- 注明:"本 PR 部分代码由 AI Agent 生成,已经过人工审查"
等待 Code Review:
• 团队成员进行 Code Review
• 根据反馈进行修改
• 修改后重复"代码审查"和"决策与提交"流程
合并后清理:
• PR 合并后删除远程分支
• git checkout main && git pull
• git branch -d feature/xxx(删除本地分支)
常见问题
为什么要用 auto + glob 模式而不是 always 模式配置 Project Rules?
使用 auto + glob 模式的好处:
• Agent 只在修改对应代码时加载相关规则(例如修改前端代码时才加载前端规则)
• token 使用量减少 70%
• Agent 不会被无关规则干扰,专注于当前任务
• 配置示例:type: auto, glob: "src/frontend/**/*.{ts,tsx}"
实测效果:在中型项目中,改用 auto 模式后,Agent 的响应速度提升了 50%,而且更准确理解任务要求。
按职责拆分和按文件拆分任务有什么区别?为什么推荐前者?
• 先写前端→再写后端→最后写数据库
• 写前端时不知道后端接口长什么样,只能猜
• 写后端时发现前端传参不对,得回去改
• 数据库模型设计不合理,前后端又要改一遍
• 来回返工,效率反而更低
按职责拆分(纵向拆分)的优势:
• 每个任务是完整的功能点(前端+后端+数据库)
• 例如:任务1实现基础注册流程,任务2增强验证,任务3优化体验
• 做完任务1就能跑起来测试,不用等所有功能完成
• 前后端一起做,接口问题当场发现
• Agent 更容易理解任务目标,不会搞混
实测数据:用按职责拆分方式,Agent 一次成功率从 60% 提升到 85%。
Cursor Checkpoint 和 Git 分支有什么区别?应该用哪个?
Cursor Checkpoint 的特点:
• 快速创建和回滚,不需要处理 Git 历史
• 适合实验性改动或不确定的任务
• 回滚后所有改动立即撤销,不留痕迹
• 缺点:Checkpoint 不会被推送到远程,只存在本地
Git 分支的特点:
• 隔离改动,不影响主分支
• 保留完整的 commit 历史,方便追溯
• 可以推送到远程,团队协作更方便
• 回滚需要使用 git reset 或 git revert
推荐的组合使用方式:
1. 开始任务前:创建 Git 分支(隔离改动)+ 创建 Checkpoint(快速回滚)
2. Agent 完成后:小问题回滚 Checkpoint,大问题 git reset --hard
3. 测试通过后:git commit(保留历史),删除 Checkpoint(不再需要)
这样既有 Checkpoint 的快速回滚能力,又有 Git 的版本管理优势。
如何判断任务是否需要开启 Long Context 模式?
适合开启 Long Context 的场景:
• 跨模块重构(涉及 5 个以上文件)
• 复杂功能开发(需要理解多个模块的交互)
• 修复涉及多个文件的 bug
• 优化性能时需要查看调用链
不需要开启的场景:
• 修改单个函数或组件
• 简单的 bug 修复(只涉及 1-2 个文件)
• 添加注释或文档
• 代码格式化
判断标准:
• 任务涉及文件数 ≤ 3:不开启
• 任务涉及文件数 4-6:根据复杂度决定
• 任务涉及文件数 ≥ 7:开启,并手动用 @ 引用关键文件
实用技巧:如果不确定,先不开启,看 Agent 的表现。如果发现它找不到关键文件或理解不全面,再开启 Long Context 重新执行任务。
Agent 改的代码大概有多少会有问题?哪些问题最常见?
问题分布:
• 5% 是严重 bug(逻辑错误、安全漏洞、数据丢失风险)
• 10% 是代码质量问题(性能低下、可维护性差、重复代码)
• 5% 是"虽然能跑但不符合项目规范"(命名不规范、缺少注释等)
最常见的问题类型:
1. 业务逻辑理解错误(占比最高)
- Agent 按字面意思实现,忽略隐含的业务规则
- 例如:实现"删除用户"时物理删除而非软删除
2. 边界条件处理不完整
- 空值、异常情况、并发冲突等特殊情况
3. 性能问题
- N+1 查询、内存泄漏、全量数据加载等
4. 安全风险
- SQL 注入、XSS、敏感信息泄露、权限检查缺失
如何应对:
• 不要完全信任 Agent 的代码,必须进行 Code Review
• 重点审查业务逻辑、边界条件、性能和安全
• 建立自动审查规则(.cursorrules 的 code_review_rules)
• 要求 Agent 完成任务后先自审查再提交
发现问题后:小问题手动修复或让 Agent 针对性修改,大问题直接回滚重来。
如何避免 Agent 修改不该修改的文件?
明确限定修改范围:
• 在任务描述最后加一句:"不要修改其他文件"
• 实测:加这句话后,乱改代码的概率从 30% 降到 5% 以下
使用白名单+黑名单:
• 明确可以修改的范围:"可以修改:src/api/** 下的所有文件"
• 明确禁止修改的范围:"不要修改:src/api/legacy/** (这是旧代码)"
• 这样既给了自由度,又避免碰不该碰的东西
用 @ 语法引用关键文件:
• 明确列出所有需要修改的文件
• 例如:"涉及这几个文件:@src/routes/auth.ts, @src/middleware/jwt.ts"
• Agent 会优先关注这些文件,减少误改其他文件的概率
利用 git diff 及时发现:
• Agent 完成后立即运行 git diff --stat
• 检查改动的文件列表是否符合预期
• 如果发现无关文件被修改,立即回滚或手动恢复
配置 .cursorrules:
• 添加规则:"未经明确授权,不要修改核心模块代码"
• 在关键目录添加注释说明不要修改的原因
这些方法组合使用,能将 Agent 误改文件的概率降到最低。
测试驱动开发(TDD)如何帮助 Agent 更好地完成任务?
传统方式的问题:
• Agent 实现功能后,你不知道它理解得对不对
• 可能已经改了十几个文件,发现方向错了
• 返工成本高,而且可能已经破坏了其他功能
TDD 的优势:
• 测试用例定义了预期行为,Agent 有明确的目标
• Agent 会专注于"让测试通过",不会无限发散
• 测试失败立即发现问题,及时止损
• 测试本身就是文档,将来维护代码时一目了然
具体工作流程:
1. 手动编写测试用例(或让 Agent 写,但你要审查)
2. 运行测试,确认失败(因为功能还没实现)
3. 让 Agent 实现功能:"实现XX功能,让 @test/xxx.test.ts 里的测试通过"
4. Agent 完成后运行测试:通过→提交,失败→检查代码或回滚
实际案例:
• 用 TDD 重构认证模块,Agent 七次搞定,完全没跑偏
• 不用测试时,同样的任务 Agent 搞了十几次还在出 bug
关键点:测试用例质量决定 Agent 的表现。测试写得好,Agent 就能精准实现;测试写得模糊,Agent 就会乱猜。
17 分钟阅读 · 发布于: 2026年1月10日 · 修改于: 2026年3月22日



评论
使用 GitHub 账号登录后即可评论