Cursor Agent 大規模プロジェクト実践:ファイルが見つからない・コード修正ミスの 7 つの対処法
画面に 3 つ目のエラーが飛び出した。
さきほど Cursor Agent にログインモジュールのリファクタリングを任せた——対象は 5 ファイル。フロントエンドのフォームコンポーネント、API ルート、認証ミドルウェア、ユーザーモデル、Redis キャッシュ層。タスクを投げて 2 分ほどで、Agent は自信満々に「完了しました」と返した。実行したら……クラッシュ。
調べてみると、Agent は 4 ファイルを見つけたが、修正したのは 3 つだけ。さらに厄介なのは、もともと正しかったミドルウェアのロジックまで「最適化」してしまい、すべてのログインリクエストが 401 を返すようになったこと。30 分かけて手動ロールバックし、依存関係を整理し直し、残りは自分で片付けた。
その瞬間、こう思った——AI プログラミングアシスタントは、本当に大規模プロジェクト向きなのか?
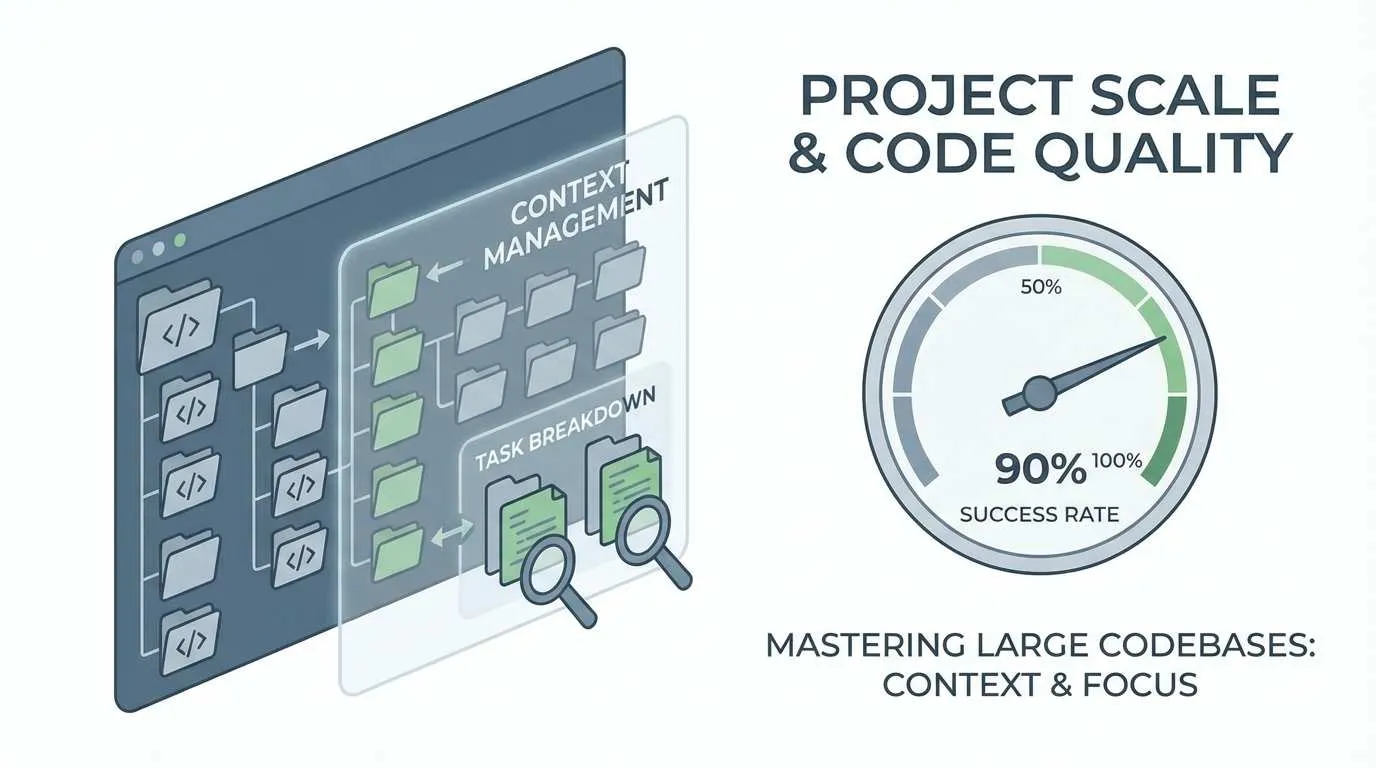
その後 2 週間、Cursor Agent の仕組みを調べ、技術ブログを十数本読み、実プロジェクトで試行錯誤を重ねた。大規模プロジェクトで Agent を信頼できるようにする方法が見えてきた。今では Agent でリファクタリングしたときの成功率が 50% 未満から 90% 超まで上がっている。
この記事では、コンテキスト管理、タスク分割、コードレビューの 3 軸から、7 つの実践テクニックを紹介する。理論ではなく、実際のプロジェクトで踏んだ落とし穴からまとめた経験だ。
なぜ Agent は大規模プロジェクトで問題を起こしやすいのか
テクニックに入る前に、失敗の理由を押さえておこう。Agent が「頭が悪い」わけではなく、3 つの客観的制約がある。
コンテキスト制限が最大のボトルネック
200k トークンを謳う大規模モデルでも、実プロジェクトでは足りない。中規模のフロントエンドとバックエンドに分離されたプロジェクトでも、主要コードだけで 100 ファイル超、各ファイルは数百〜数千行。package.json、設定、テストコード……全部入れると、すぐトークン上限を超える。
Agent はプロジェクトを「丸ごと見る」ことはできない。見えるのは、対話で言及されたファイルと、Cursor の自動インデックスがなんとかつないだ一部の依存関係だけ。視界 5 メートルの人にサッカー場で探し物をさせるようなもの——見落としは必然だ。
React + Node.js プロジェクトで同じ要件を試した。小規模(20 ファイル)では一回成功率 85%、中規模(50 ファイル)で 60%、大規模(100+ ファイル)では 35% まで落ちた。差ははっきりしている。
Agent の「近視眼」問題
Agent は間接依存のファイルを特に見落とす。
API ルートの修正を頼むと、ルートと Controller は素直に直す。ところが Controller がユーティリティ関数を呼び、それが設定モジュールに依存……こうした隠れた依存チェーンは、2 層目で追跡をやめることが多い。
最も厄介なのが近接バイアス。最近開いたファイルや、対話で明示されたファイルを優先する。過去のチャットで触れたファイルが、今のタスクと無関係でも引っ張り出して適当に直す。逆に、本当に直すべきファイルを言わないと、見落とす。
全体視点の欠如
これが最も致命的。
人間は手を動かす前に、頭の中でアーキテクチャを走査する。この機能はどのモジュールに関わる? モジュール間はどう通信する? A を変えると B へ影響する? Agent にはそれがない。毎回「局所最適」——今の範囲だけ見て、もっともそれらしい案で手を入れる。
最悪の例:DB クエリのパフォーマンス最適化を依頼した。Agent はインデックス追加と SQL 調整を真面目にやり、確かに速くなった。3 日後、システムがメモリ不足で落ちた。キャッシュ層に全データのプリロードを足し、Redis をパンクさせていたからだ。
Agent は「全体設計」を知らない。性能問題を見れば性能を、重複コードを見れば関数抽出——元の設計意図を壊すかどうかは考えない。
コンテキスト管理の 3 つの重要テクニック
原因が分かれば対策も打てる。コンテキスト管理が最重要——Agent の「視界」を制御すれば、多くの問題は消える。
テクニック 1:Project Rules 設定の最適化
手っ取り早く always モードですべての rules を詰め込むのは、最大の誤り。
always は「毎回の対話で rules を読み込む」という意味。トークンを激しく消費する。フロント、バック、テスト、ドキュメント……モジュールごとに規約が違えば、全部 always だと Agent が動く前にトークンの 3 分の 1 が消える。
正解:Auto Attached + glob マッチング
フロントエンドとバックエンドに分離されたプロジェクトの設定例:
# .cursorrules (プロジェクトルート)
# 共通ルール(重要なものだけ残す)
- type: always
rules:
- TypeScript を使用する
- ESLint 設定に従う
- すべての非同期操作にエラー処理を必須とする
# フロントエンド(フロント修正時のみ)
- type: auto
glob: "src/frontend/**/*.{ts,tsx}"
rules:
- React Hooks を使用する
- コンポーネントに PropTypes または TypeScript 型を必須とする
- Tailwind CSS を使用し、インラインスタイルは書かない
# バックエンド(バック修正時のみ)
- type: auto
glob: "src/backend/**/*.ts"
rules:
- API ルートに入力検証を必須とする
- DB 操作にトランザクションを使用する
- 機密情報をログに出さない
# テスト
- type: auto
glob: "**/*.test.ts"
rules:
- 各テストケースに明確な説明を書く
- Jest の describe/it 構造を使うこうすると、必要なときだけ対応ルールが読み込まれる。実測でトークン使用量は 70% 減。無関係なルールに邪魔されなくなった。
小技:各ルールの末尾に「不確かなら、先に私に聞いてください」を足すと、境界ケースで勝手に推測せず質問してくるようになった。
テクニック 2:Long Context と Summarized Composers を活用
Cursor には、見落とされがちな便利機能が 2 つある。
Long Context
複雑なタスクではオンにする。Agent のコンテキストウィンドウが広がり、より多くのコードを見られる。
常時オンは NG——トークン消費が速く、思考時間も伸びる。私の習慣:
- 通常タスク(関数修正、小さなバグ):オフ
- 複雑タスク(モジュールリファクタ、機能追加):オン
- 特に複雑(モジュール横断):オン + 重要ファイルを @ で手動引用
Summarized Composers
過去対話の要約にアクセスできる。完全履歴ではなく要約なので、長期プロジェクト向き。
昨日 Agent に書かせたユーティリティ関数を、今日拡張したい。「昨日のあの関数を使って」と言っても見つけられないことがある。Summarized Composers が有効なら、要約から関連箇所を引いてくれる。
大きな機能モジュールが終わるたびに新しい Chat を開き、冒頭に「以前 XX 機能を実装済み。コードは XX ディレクトリ」と書く。履歴を参照しつつ、細部に足を取られない。
テクニック 3:コンテキスト範囲を能動的に管理
最重要。かつ、最も見落とされやすい。
Agent にファイル探索を任せない。何を見て、何を見ないか、自分で指定する。
@ 構文で重要ファイルを引用
ユーザー認証フローをリファクタリングしてください。関係ファイル:
@src/routes/auth.ts(認証ルート)
@src/middleware/jwt.ts(JWT ミドルウェア)
@src/models/User.ts(ユーザーモデル)
@src/utils/password.ts(パスワード暗号化)
他のファイルは修正しないでください。最後の一文が効く。実測で、無関係な修正の確率が 30% から 5% 以下に下がった。
修正範囲を限定
src/frontend/components/auth/ 配下にパスワードリセットコンポーネントを追加。
他ディレクトリは触らないでください。ホワイトリスト + ブラックリスト
修正可:src/api/** 配下のすべて
修正不可:src/api/legacy/**(旧コード、廃止予定)自由度を保ちつつ、触れてはいけない場所を守れる。
タスクを渡す前に「最大で何ファイル? どのディレクトリ?」を頭の中で整理し、範囲を明示する習慣をつけている。面倒に聞こえても、後のバグ修正時間を大幅に節約できる。
タスク分割の 2 つの黄金律
コンテキストで「見えない」問題は抑えられる。だがタスクが複雑すぎると、見えていても失敗する。ここでタスク分割。
テクニック 4:職責で分割(ファイル単位ではない)
最大の落とし穴。
最初は「ファイルごとに分ければいい」と思っていた。ユーザー登録なら:
- フロントのフォーム
- バックの API
- DB モデル
合理的に見える。実行すると毎段階で問題が出る:
- フロント時点では API の形が分からず推測
- バックでパラメータ不一致、フロントに戻る
- DB で型が合わず、前後を直し直す
行ったり来たりで、かえって遅い。
正解:機能職責で縦分割
同じユーザー登録を、今はこう分ける:
ステップ 1:基本登録フロー(最小実行可能版)
タスク 1:最小限のユーザー登録
- フロント:ユーザー名・パスワードのみのフォーム
- バック:登録 API + 基本検証
- DB:User モデル(最小フィールド)
目標:登録が通ることステップ 2:検証とセキュリティ
タスク 2:登録検証・セキュリティ
- メール形式検証
- パスワード強度
- 重複登録防止
- パスワード暗号化保存ステップ 3:UX 改善
タスク 3:登録体験の最適化
- リアルタイムバリデーション
- 登録後の自動ログイン
- ウェルカムメール各タスクは「縦方向」——フロントからバック、DB まで、独立した機能点を完結させる。
メリット:
- 独立テスト可能:タスク 1 終了時点で動かせる
- 手戻り減:フロントエンドとバックエンドを同時に進め、API 問題をその場で発見
- Agent が理解しやすい:目標が明確
実測:職責分割で一回成功率 60% → 85%。
テクニック 5:明確なチェックポイントを設定
何度も助けられたテクニック。
大規模プロジェクトの致命傷——長時間変更後に方向が間違っていたと気づき、戻せない。Agent は「保存しますか?」と聞かず、いきなり直す。気づいたときには十数ファイル変更済み。
Checkpoint 機能
Cursor の Checkpoint(チェックポイント)は過小評価されている。
# Cursor で Cmd/Ctrl + Shift + P
# "Create Checkpoint" を入力
# メモ:ログインモジュールリファクタ前Agent に作業させ、おかしければワンクリックで checkpoint へロールバック。
習慣:
- 大タスク開始時:checkpoint 作成
- Agent 完了後:テスト OK → 削除、NG → ロールバック
- 小タスク連続:2〜3 個ごとに checkpoint
Agent が失敗しても、せいぜい 1 小タスク分の損失で済む。
テスト駆動開発(TDD)
さらに進んだやり方——先にテスト、後に実装。
1. テストケースを書く(期待動作を定義)
2. テスト実行、失敗を確認
3. Agent に「テストが通るまで実装」
4. 通らなければ理解ミス——即停止テストが明確な終了条件になる。Agent は「テストを通す」に集中し、無限発散しない。
Node.js プロジェクトで認証モジュール全体を TDD リファクタしたら、Agent は 7 回で完了、方向逸脱ゼロ。テストなしの同タスクは十数回試してもバグだらけだった。
コードレビューと監視の 2 つの重要実践
「ミスを減らす」話はここまで。ゼロにはできない。最後の防衛線はレビューと監視——早期発見、早期止血。
テクニック 6:多層的なレビュー基準
「AI を使うから Code Review 不要」——正反対。AI ほど Review が重要。
Agent のミスは隠れやすい。文法 OK、ロジックも一見通る。でも「違和感」がある。人間なら一瞬で気づく問題を、Agent は自覚しない。
Cursor Rules で自動レビュー
# .cursorrules(レビュー部分)
code_review_rules:
critical:
- "パスワード、API キーなどをハードコードしない"
- "DB 操作はパラメータ化クエリで SQL インジェクションを防ぐ"
- "外部入力は必ず検証・サニタイズ"
warning:
- "関数は 50 行以内、長ければ分割"
- "any を避け、型を明確に"
- "非同期は try-catch または .catch() でエラー処理"
info:
- "単体テスト追加を検討"
- "複雑ロジックにコメント"
- "重複コードは共通関数へ"Agent 完了後:
タスク完了。.cursorrules の code_review_rules で自己レビューし、
critical と warning の問題をすべて列挙してください。自分で書いたコードでも、別視点の自己レビューで問題を拾えることが多い。
人間 + Agent の段階レビュー
- Agent 一次(自動):構文、規約
- 人間重点:ビジネスロジック、境界条件、パフォーマンス(N+1 等)、セキュリティ(SQLi、XSS)
- テスト:既存機能を壊していないか
一行ずつ見ない——時間の無駄。重要なロジックとリスクに絞り、残りはツールとテストへ。
大規模プロジェクトでの統計:Agent 修正の 15〜20% に問題。
- 5%:深刻(ロジック、セキュリティ)
- 10%:品質(性能、保守性)
- 5%:動くが規約外
レビューを省略すると、数週間後に表面化し、調査コストは遥かに高くなる。
テクニック 7:Git は最後の保険
基本中の基本。軽視する人が多い。
git diff を使う
Agent 完了後、最初にやるのはテストではなく:
git diffどのファイルが、どう変わったか。毎回確認:
- 変更量は想定内か(数十ファイルなら警戒)
- 無関係ファイルの変更はないか
- 重要ロジックが触られていないか
git diff --stat で概要を先に見る:
git diff --stat
# 出力例:
# src/api/auth.ts | 25 +++++---
# src/models/User.ts | 12 ++--
# src/utils/password.ts | 3 +-
# src/config/database.ts | 150 ++++++++++++++++++++++++++++++++++++++++++++++150 行増えているのに、タスクにそのファイルが含まれていない……すぐ確認。
Checkpoint + Git の二重保険
1. タスク開始前:
- git checkout -b feature/xxx
- Cursor Checkpoint 作成
2. Agent 完了後:
- git diff
- テスト実行
- OK → git commit
- NG → 小問題は手動/Agent 修正、大問題は Checkpoint または git reset --hard
3. 確認後:
- git push
- Pull Request- Checkpoint:速いロールバック、履歴を汚さない
- Git ブランチ:隔離、メインを守る
- commit:変更記録を残す
Agent タスクの commit には注記を入れる:
git commit -m "feat: ユーザー登録機能追加 (by AI Agent)"後から見て Agent 生成と分かれば、調査時に注意深く見られる。
結論
冒頭の深夜 1 時の場面に戻ろう。
今なら、ログインモジュールのリファクタをこう進める:
- コンテキスト管理:認証モジュール用 .cursorrules、関連ルールのみ。@ で 5 ファイルを列挙し「この 5 つのみ修正」と明示
- タスク分割:一気に全部やらず、基本ログイン → 検証追加 → キャッシュ最適化の順
- コードレビュー:小タスクごとに git diff、テスト、問題なければ次へ
こうすると、ファイル未発見の確率 50% → 10% 未満、修正ミス 30% → 5% 以下。追加時間はタスクあたり 5〜10 分。
AI プログラミングツールは万能ではない。アーキテクチャ設計、ビジネス理解、品質責任は人間の仕事。ただし使い方を学べば、開発効率は確実に上がる——Agent を「管理」することが前提。
コンテキスト管理、タスク分割、コードレビュー——3 軸はどれも欠かせない。コンテキストで「見せ」、分割で「正しくやらせ」、レビューで「安心させる」。
提案:今 Cursor Agent で大規模開発しているなら、10 分だけ Project Rules を見直してみて。always を auto + glob に変えるだけで、トークンを大幅節約し、Agent の精度が一段上がる。
技術は進み、ツールも変わる。変わらない原則:要件を明確に、タスクを分割し、継続的に検証する。AI プログラミングにも、複雑プロジェクト全般にも当てはまる。
あなたは Cursor Agent でどんな落とし穴に遭遇しましたか?コメントで経験をシェアしてください。
Cursor Agent 大規模プロジェクト開発の完全フロー
タスク開始から最終確認までのワークフロー。大規模プロジェクトで Agent を効率的かつ確実に動かす
Estimated time: PT30M
-
1
Step 1: タスク準備:コンテキストとチェックポイント
コンテキスト管理が成功の鍵。開始前の準備: -
2
Step 2: タスク実行:Agent の作業範囲を精密に制御
実行段階では見落とし・誤修正を防ぐ: -
3
Step 3: コードレビュー:多層的な変更確認
Agent 完了後、コミット前に多層レビュー: -
4
Step 4: 決定とコミット:テスト合格後
レビュー・テスト結果で次を決める: -
5
Step 5: 最終確認:プッシュと PR
問題なければリモートへ:
FAQ
Project Rules は、なぜ always ではなく auto + glob モードで設定すべきですか?
auto + glob モードの利点:
• Agent は対応するコードを修正するときだけ関連ルールを読み込む(例:フロントエンド修正時のみフロントエンドルール)
• トークン使用量を 70% 削減できる
• 無関係なルールに邪魔されず、今のタスクに集中できる
• 設定例:type: auto, glob: "src/frontend/**/*.{ts,tsx}"
実測:中規模プロジェクトで auto に切り替えたあと、Agent の応答速度は 50% 向上し、タスク要件の理解もより正確になりました。
職責による分割とファイルによる分割、何が違いますか?なぜ前者を推奨するのですか?
• フロントエンド→バックエンド→データベースの順で進める
• フロントエンドを書く段階ではバックエンド API の形が分からず、推測頼みになる
• バックエンドを書くとフロントエンドのパラメータが合わず、戻って修正
• DB モデル設計がずれると、前後両方を直し直す
• 手戻りが増え、かえって遅くなる
職責による分割(縦方向)の利点:
• 各タスクが完結した機能点(フロント + バック + DB)になる
• 例:タスク 1 で基本登録、タスク 2 で検証強化、タスク 3 で UX 改善
• タスク 1 が終われば動かしてテストでき、全機能完成を待たなくてよい
• フロントエンドとバックエンドを同時に進めるので、インターフェース問題をその場で発見できる
• Agent がタスク目標を理解しやすく、混同しにくい
実測:職責分割にすると、Agent の一回成功率は 60% から 85% に上がりました。
Cursor Checkpoint と Git ブランチの違いは?どちらを使うべきですか?
Cursor Checkpoint の特徴:
• 素早く作成・ロールバックでき、Git 履歴をいじらなくてよい
• 実験的な変更や不確かなタスク向け
• ロールバック後、変更は即座に消え、痕跡が残らない
• 欠点:リモートにプッシュできず、ローカルのみ
Git ブランチの特徴:
• 変更を隔離し、メインブランチに影響しない
• commit 履歴が残り、追跡しやすい
• リモートにプッシュでき、チーム協業に向く
• ロールバックには git reset や git revert が必要
推奨フロー:
1. タスク開始前:Git ブランチ作成(隔離)+ Checkpoint 作成(素早いロールバック用)
2. Agent 完了後:小さな問題は Checkpoint ロールバック、大きな問題は git reset --hard
3. テスト合格後:git commit(履歴保存)、Checkpoint 削除(不要になるため)
Checkpoint の速さと Git のバージョン管理を両立できます。
Long Context モードをオンにすべきか、どう判断しますか?
オンに向く場面:
• モジュール横断リファクタリング(5 ファイル以上)
• 複数モジュールの連携を理解する複雑な機能開発
• 複数ファイルにまたがるバグ修正
• 呼び出しチェーンを追うパフォーマンス最適化
オンに不要な場面:
• 単一関数・コンポーネントの修正
• 1〜2 ファイルの単純なバグ修正
• コメント・ドキュメント追加
• コードフォーマット
判断基準:
• 関与ファイル ≤ 3:オフ
• 関与ファイル 4〜6:複雑さ次第
• 関与ファイル ≥ 7:オン + @ で重要ファイルを手動引用
迷ったらまずオフで様子を見る。重要ファイルを見つけられない、理解が浅いと感じたら Long Context をオンにして再実行しましょう。
Agent が修正したコードに問題はどのくらいありますか?よくある問題は?
内訳:
• 5%:深刻なバグ(ロジックエラー、セキュリティ脆弱性、データ損失リスク)
• 10%:コード品質(低パフォーマンス、保守性、重複コード)
• 5%:「動くが規約に合わない」(命名、コメント不足など)
よくある問題:
1. ビジネスロジックの理解ミス(最多)
- 字面どおり実装し、暗黙のルールを無視
- 例:「ユーザー削除」を論理削除ではなく物理削除
2. 境界条件の処理不足
- 空値、異常系、同時実行競合
3. パフォーマンス
- N+1 クエリ、メモリリーク、全量ロード
4. セキュリティ
- SQL インジェクション、XSS、機密漏洩、権限チェック漏れ
対策:
• Agent のコードを盲信せず Code Review 必須
• ビジネスロジック、境界条件、パフォーマンス、セキュリティを重点確認
• 自動レビュールール(.cursorrules の code_review_rules)を整備
• タスク完了後、提出前に Agent に自己レビューさせる
発見後:小さな問題は手動修正か Agent にピンポイント修正、大きな問題はロールバックしてやり直し。
Agent が触るべきでないファイルを修正するのを、どう防ぎますか?
修正範囲を明示:
• タスク説明の最後に「他のファイルは修正しないでください」を追加
• 実測:この一言で、無関係な修正の確率が 30% から 5% 以下に低下
ホワイトリスト + ブラックリスト:
• 修正可:「src/api/** 配下のすべてのファイル」
• 修正不可:「src/api/legacy/**(旧コード、廃止予定)」
• 自由度を保ちつつ、触れてはいけない場所を守れる
@ 構文で重要ファイルを列挙:
• 修正対象をすべてリスト
• 例:「関係ファイル:@src/routes/auth.ts, @src/middleware/jwt.ts」
• Agent はこれらを優先し、誤修正が減る
git diff で即確認:
• Agent 完了後すぐ git diff --stat
• 変更ファイルが想定どおりか確認
• 無関係な変更があれば即ロールバックまたは手動復元
.cursorrules の設定:
• 「明示的な承認なしにコアモジュールを修正しない」
• 重要ディレクトリに修正禁止理由のコメント
組み合わせれば、誤修正の確率を最小化できます。
テスト駆動開発(TDD)は、Agent のタスク遂行をどう助けますか?
従来方式の問題:
• 機能実装後、理解が正しいか分からない
• 十数ファイル変更後に方向の誤りに気づく
• 手戻りコストが高く、他機能を壊している可能性も
TDD の利点:
• テストケースが期待動作を定義し、Agent に明確な目標がある
• 「テストを通す」ことに集中し、無限発散しない
• 失敗ですぐ問題を発見し、損失を抑えられる
• テスト自体がドキュメントになり、将来の保守も楽
ワークフロー:
1. テストケースを手動作成(または Agent に書かせて人間がレビュー)
2. テスト実行、失敗を確認(未実装のため)
3. Agent に実装依頼:「@test/xxx.test.ts のテストが通るように XX 機能を実装して」
4. 完了後テスト:合格→コミット、失敗→確認またはロールバック
実例:
• TDD で認証モジュールをリファクタリング → Agent は 7 回で完了、方向逸脱なし
• テストなしの同タスク → 十数回試してもバグ続出
要点:テストの質が Agent の出来を決める。テストが明確なら Agent も正確、曖昧なら当てずっぽう。
7分で読めます · 公開日: 2026年1月10日 · 更新日: 2026年6月15日
Cursor 完全ガイド
検索からこのページに来た場合は、前後の記事もあわせて読むと同じテーマの理解がかなり早く深まります。
前の記事
Cursor Rules 上級設定:自分専用の AI コーディングアシスタントを作る
Cursor Rules の上級設定を学び、自分専用の AI コーディングアシスタントを作りましょう。ルールシステムの進化、MDC 形式、実戦的な設定例、デバッグと最適化のコツを解説し、複数の実プロジェクトの完全なルールを提供して開発効率を高めます。
第 6 / 25 記事
次の記事
Cursor Agent モード実戦:3 ヶ月かけて掴んだ 10 のコツ
深夜 2 時のバグ地獄から阿吽の呼吸へ。Cursor Agent モードの実戦経験、落とし穴、効率化のコツを共有し、AI プログラミングアシスタントを本当に使いこなす方法を解説します
第 8 / 25 記事
関連記事
もう使い方を間違えるな!Cursor 3 機能の正しい開き方

もう使い方を間違えるな!Cursor 3 機能の正しい開き方
Cursor Agent モード完全ガイド:3 ステップで始める自動化プログラミング(2026 年最新)

Cursor Agent モード完全ガイド:3 ステップで始める自動化プログラミング(2026 年最新)
Cursor Agent Mode 完全ガイド:AI アシスタントにプログラミングを任せる

コメント
GitHubアカウントでログインしてコメントできます