Cursor Agent 大規模プロジェクト実践:ファイルが見つからない、コード修正ミスを解決する7つの方法
深夜1時、私は画面に表示された3つ目のエラーメッセージを見つめ、キーボードの上に指を置いたまま、なかなか叩くことができませんでした。
先ほど、Cursor Agent にログインモジュールのリファクタリングを依頼しました。このモジュールは、フロントエンドのフォームコンポーネント、API ルート、認証ミドルウェア、ユーザーモデル、Redis キャッシュ層の5つのファイルに関わっています。タスクを送信した後、Agent は2分間作業し、自信満々に「完了しました」と言いました。期待を込めてコードを実行した結果…クラッシュしました。
一通りチェックしてようやく分かりました。Agent は4つのファイルを見つけましたが、そのうち3つしか修正していませんでした。さらに致命的だったのは、本来正しかったミドルウェアのロジックまで「最適化」してしまい、結果としてすべてのログインリクエストが401を返すようになっていたのです。私は30分かけて手動でコードをロールバックし、依存関係を整理し直し、残りの作業を自分で終わらせました。
正直、その瞬間は疑いました。「AI プログラミングアシスタントは本当に大規模プロジェクトを扱えるのか?」と。
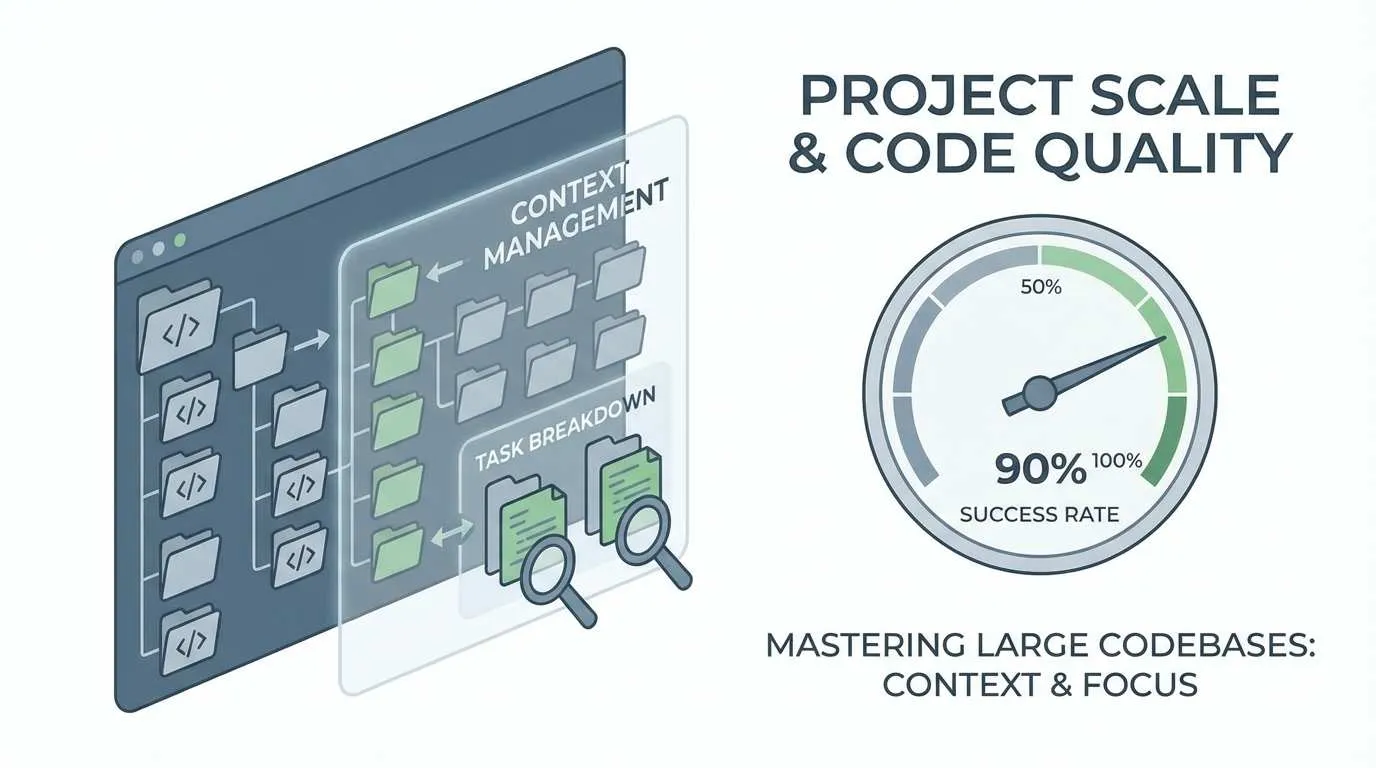
その後、私は2週間かけて Cursor Agent の仕組みを研究し、十数本の技術ブログを読み、実際のプロジェクトで試行錯誤を繰り返しました。そして徐々に、大規模プロジェクトで Agent をより確実に動かすための方法論を見つけ出しました。今では、Agent を使ったコードリファクタリングの成功率は50%未満から90%以上に向上しました。
この記事では、コンテキスト管理、タスク分割、コードレビューの3つの次元から、7つの実践テクニックを共有します。これらは理論的な推測ではなく、実際のプロジェクトでの失敗から得られた経験則です。
なぜ Agent は大規模プロジェクトで問題を起こしやすいのか
テクニックを紹介する前に、なぜ Agent が失敗するのかを理解する必要があります。Agent が「頭が悪い」からではなく、3つの客観的な制約があるからです。
コンテキスト制限が最大のボトルネック
ご存知のように、200kトークンを謳う大規模モデルであっても、実際のプロジェクトでは耐えられません。中規模の前後分離プロジェクトであれば、主要なコードファイルだけで100以上あり、各ファイルは数百から数千行になります。さらに package.json、設定ファイル、テストコード…すべてを含めると、簡単にトークン上限を突破します。
Agent はプロジェクトを「完全に見る」ことができません。見えるのは、現在の対話で言及されたいくつかのファイルと、Cursor の自動インデックスシステムが辛うじて関連付けた一部の依存関係だけです。これは、視界5メートルの人がサッカースタジアムで探し物をするようなもので、見落としは必然です。
私はある React + Node.js プロジェクトでテストを行いました。同じ要件でも、小規模プロジェクト(20ファイル)では Agent の一回成功率は85%でしたが、中型プロジェクト(50ファイル)では60%に落ち、大型プロジェクト(100+ファイル)では35%まで崩壊しました。その差は明らかです。
Agent の「近視眼」問題
興味深い現象があります。Agent は間接的に依存するファイルを特によく「見落とす」のです。
例えば API ルートの修正を依頼すると、ルートファイルと対応する Controller は素直に修正します。問題は、その Controller があるユーティリティ関数を呼び出しており、そのユーティリティ関数がさらに設定モジュールに依存しているような場合…この隠れた依存チェーンを、Agent はしばしば2層目で追跡を止めてしまいます。
最も厄介なのは近接バイアスです。Agent は最近開いたファイルや対話の中で明示的に言及されたファイルを優先的に注目します。過去のチャットログで言及されたファイルがあれば、たとえ現在のタスクと関係なくても、Agent はそれを持ち出して適当に修正してしまう可能性があります。逆に、本当に修正が必要な重要ファイルでも、明言しなければ見落とします。
全体的視点の欠如
これが最も致命的です。
人間の開発者は作業に取り掛かる前、頭の中で全体アーキテクチャをシミュレーションします。「この機能はどのモジュールに関わるか?各モジュールはどう通信するか?Aを変えるとBに影響するか?」しかし、Agent はそうしません。毎回タスクを実行するたびに「局所最適化」を行います。現在の範囲内のコードだけを見て、最も合理的と思われる案を探し、手を動かします。
私が見た中で最も酷いケースは、Agent にデータベースクエリのパフォーマンス最適化を依頼したときのことです。Agent は真面目にクエリにインデックスを追加し、SQL 文を調整しました。確かに速くなりました。しかし3日後、システムが突然メモリ不足でダウンしました。原因は、Agent が「最適化」のためにキャッシュ層に全データのプリロードロジックを追加し、Redis の容量をパンクさせていたからでした。
Agent は「全体アーキテクチャ設計」というものを知りません。パフォーマンス問題を見ればパフォーマンスを最適化し、重複コードを見れば関数を抽出しますが、それが元の設計意図を壊すかどうかは全く気にしません。
コンテキスト管理の3つの核心テクニック
問題の所在が分かったので、対策を打てます。コンテキスト管理は最重要事項です。Agent が「見える」範囲をうまく制御すれば、多くの問題は自然と消えます。
テクニック1:Project Rules 設定の最適化
多くの人が手っ取り早く済ませようとして、always モードですべてのプロジェクトルールを詰め込みますが、これは最大の誤りです。
always モードは「毎回の対話でこれらのルールをロードする」という意味です。聞こえはいいですが、トークンを激しく消費します。プロジェクトにはフロントエンド、バックエンド、テスト、ドキュメントなど複数のモジュールがあり、それぞれのコーディング規範が異なります。すべて always でロードすると、Agent が作業を始める前にトークンの3分の1が消えてしまいます。
正解:Auto Attached + glob マッチングを使用する
例えば、私がメンテナンスしている前後分離プロジェクトの設定はこうです:
# .cursorrules (プロジェクトルート)
# 共通ルール(最も核心的なものだけ残す)
- type: always
rules:
- TypeScript を使用する
- ESLint 設定に従う
- すべての非同期操作にはエラー処理を必須とする
# フロントエンドルール(フロントエンドコード修正時のみロード)
- type: auto
glob: "src/frontend/**/*.{ts,tsx}"
rules:
- React Hooks を使用する
- コンポーネントには PropTypes または TypeScript 型を必須とする
- Tailwind CSS を使用し、インラインスタイルは書かない
# バックエンドルール(バックエンドコード修正時のみロード)
- type: auto
glob: "src/backend/**/*.ts"
rules:
- API ルートには入力検証を必須とする
- データベース操作にはトランザクションを使用する
- 機密情報をログに記録しない
# テストルール
- type: auto
glob: "**/*.test.ts"
rules:
- 各テストケースには明確な説明を記述する
- Jest の describe/it 構造を使用するこのように設定すると、Agent は本当に必要なときだけ対応するルールをロードします。テストしたところ、トークン使用量は70%削減され、Agent が無関係なルールに妨害されることもなくなりました。
ちょっとしたコツですが、各ルールの最後に「不確かな場合は、まず私に聞いてください」と付け加えると効果的です。これを追加してから、Agent が境界ケースに遭遇したときに勝手に推測せず、自発的に質問してくるようになりました。
テクニック2:Long Context と Summarized Composers の活用
Cursor には非常に便利ですが見落とされがちな2つの機能があります。
Long Context
これはスイッチオプションで、複雑なタスクを処理するときはオンにすることを忘れないでください。有効にすると、Agent はより大きなコンテキストウィンドウを使用し、より多くのコードを見ることができます。
ただし、常時オンにはしないでください。トークンを急速に消費し、Agent の思考時間が長くなります。私の習慣は:
- 通常タスク(関数の修正、バグ修正):オフ
- 複雑なタスク(モジュールリファクタリング、機能追加):オン
- 特に複雑なタスク(モジュール間リファクタリング):オン + 重要ファイルの手動引用
Summarized Composers
この機能により、Agent は完全な履歴ではなく、以前の対話の要約にアクセスできます。長期的なプロジェクトに特に適しています。
例えば、昨日 Agent にユーティリティ関数を書いてもらい、今日それを拡張したいとします。「昨日のあの関数を使って」と直接言っても、Agent は見つけられないかもしれません。しかし Summarized Composers が有効であれば、過去の対話要約を自動検索し、関連内容を見つけてくれます。
私の現在のワークフローは、大きな機能モジュールを完了するたびに新しい Chat ウィンドウを作成し、冒頭に「このプロジェクトでは以前 XX 機能を実装しました。コードは XX ディレクトリにあります」と一言添えることです。これにより、歴史的なコンテキストを引用しつつ、過度な詳細に足を引っ張られることもありません。
テクニック3:コンテキスト範囲の能動的な管理
これが最も重要で、かつ最も見落としがちな点です。
Agent が自分で全ファイルを見つけることを期待してはいけません。何を見るべきで、何を見るべきでないか、あなたが能動的に教える必要があります。
重要ファイルの引用:@ 構文を使用
タスクを説明する際、@ファイル名 で重要ファイルをリストアップします:
ユーザー認証フローのリファクタリングをお願いします。以下のファイルが関係します:
@src/routes/auth.ts (認証ルート)
@src/middleware/jwt.ts (JWTミドルウェア)
@src/models/User.ts (ユーザーモデル)
@src/utils/password.ts (パスワード暗号化ツール)
他のファイルは修正しないでください。最後の「他のファイルは修正しないでください」という一文が重要です。テストしたところ、この一文を追加した後、Agent が無関係なコードを勝手に修正する確率は30%から5%以下に下がりました。
修正範囲の限定
タスクが特定のサブディレクトリのみに関わる場合、明確に伝えます:
src/frontend/components/auth/ ディレクトリ配下にパスワードリセットコンポーネントを追加してください。
他のディレクトリのコードは修正しないでください。さらに高度な使い方:ホワイトリスト + ブラックリストの組み合わせ
修正可能:src/api/** 配下の全ファイル
修正不可:src/api/legacy/** (これは古いコードで廃止予定)これにより、Agent に十分な自由度を与えつつ、触れてはいけないものへの接触を防げます。
私は現在、Agent にタスクを割り当てる前に、「このタスクは最大でいくつのファイルを修正すべきか?どのディレクトリに関わるか?」を頭の中でシミュレーションし、その範囲を明確に伝える習慣をつけています。面倒に聞こえるかもしれませんが、後でバグ修正にかかる大量の時間を節約できます。
タスク分割の2つの黄金律
コンテキスト管理で「Agent が見えない」問題は解決しましたが、別の落とし穴があります。見えていたとしても、タスクが複雑すぎると Agent は失敗しやすいのです。そこでタスク分割の出番です。
テクニック4:職責による分割(ファイル単位ではない)
これは私が踏んだ最大の地雷です。
最初は、タスク分割なんて簡単だと思っていました。ファイルごとに分ければいいと。例えばユーザー登録機能なら:
- まずフロントエンドのフォームコンポーネントを書く
- 次にバックエンドの API ルートを書く
- 最後にデータベースモデルを書く
合理的に見えますよね?しかし実際にやってみると、各ステップで問題が起きます:
- フロントエンドを書くとき、バックエンドのインターフェースが分からず、推測で書くしかない
- バックエンドを書くとき、フロントエンドが送ってくるパラメータが想定と違い、フロントエンドを修正しに戻る
- データベースモデルを書くとき、フィールド型が間違っていることに気づき、前後両方を修正し直す
行ったり来たりで、かえって時間がかかります。
正しい分割方法:機能職責による分割
ユーザー登録の例で言えば、今はこう分割します:
ステップ1:基本登録フローの実装(最小実行可能バージョン)
タスク1:最も基本的なユーザー登録機能を実装する
- フロントエンド:ユーザー名、パスワードの2項目のみのフォーム
- バックエンド:登録 API + 基本検証
- データベース:User モデル(最小フィールド)
目標:全フローが通るようになり、ユーザー登録が成功することステップ2:検証とセキュリティの強化
タスク2:登録検証とセキュリティ機構の追加
- メールアドレス形式検証
- パスワード強度チェック
- 二重登録防止
- パスワード暗号化保存ステップ3:ユーザー体験の向上
タスク3:ユーザー登録体験の最適化
- リアルタイムフォーム検証ヒント
- 登録成功後の自動ログイン
- ウェルカムメール送信違いが分かりますか?各タスクは「縦方向」です。フロントエンドからバックエンド、データベースまで、1つの独立した機能ポイントを完全に実装します。
この分割方式のメリットは:
- 各タスクを独立してテストできる:タスク1が終われば動かせるようになり、全機能の完成を待つ必要がない
- 手戻りの減少:前後端を一緒に作るので、インターフェースの問題をその場で発見できる
- Agent が理解しやすい:タスクの目標が明確で、混同しにくい
テストの結果、「職責による分割」方式を使うと、Agent のタスク完了の一回成功率は60%から85%に向上しました。
テクニック5:明確なチェックポイントの設定
このテクニックには何度も助けられました。
大規模プロジェクトの致命的な問題は、コードを長時間修正した後で方向性の間違いに気づき、元に戻せなくなることです。特に Agent に任せると、「保存しますか?」とは聞かず、直接修正してしまいます。おかしいと気づいた時には、すでに十数ファイルが変わっているかもしれません。
Checkpoint 機能の使用
Cursor には非常に便利ですが過小評価されている機能があります:Checkpoint(チェックポイント)。
タスクを開始する前に、checkpoint を作成します:
# Cursor で Cmd/Ctrl + Shift + P を押す
# "Create Checkpoint" を入力
# メモを入力:ログインモジュールリファクタリング前そして Agent に作業させます。もし間違いに気づいたら、ワンクリックで checkpoint の状態にロールバックでき、すべての変更を取り消せます。
私の習慣は:
- 新しい大タスクの開始ごと:checkpoint 作成
- Agent タスク完了後:テスト合格 → checkpoint 削除;テスト失敗 → checkpoint ロールバック
- 複数の小タスク:2-3個完了するごとに checkpoint 作成
こうすれば、たとえ Agent が失敗しても、せいぜい小タスク1つ分の作業量を失うだけで済みます。
テスト駆動開発(TDD)
さらに進んだ方法として、先にテストを書き、その後に Agent に機能を実装させる方法があります。
面倒に聞こえるかもしれませんが、大規模プロジェクトでは特に有効です。こうします:
1. テストケースを手動で書く(期待する動作を定義)
2. テストを実行し、失敗することを確認(機能未実装のため)
3. Agent に機能を実装させ、テストが通るまで行わせる
4. もしテストがずっと通らなければ、Agent の理解が間違っているため、即座に停止するこの方法の素晴らしい点は、テストケースが Agent にとっての明確な終了条件になることです。Agent は無限に発散することなく、「テストをパスさせる」という目標に集中します。
ある Node.js プロジェクトでこの方法を使って認証モジュール全体をリファクタリングしたところ、Agent は7回で完了し、方向性の逸脱は全くありませんでした。以前テストなしで同じタスクを行ったときは、Agent は十数回やってもバグを出していました。
コードレビューと監視の2つの重要実践
これまでは「いかに Agent にミスをさせないか」を話しましたが、どんなに注意してもミスゼロは不可能です。最後の防衛線はコードレビューと監視です。問題をタイムリーに発見し、損害を最小限に抑えます。
テクニック6:多層的なレビュー基準の確立
よくある誤解として、「AI を使っているから Code Review は不要だ」というものがあります。
正反対です。AI を使うからこそ、Code Review はより重要になります。なぜなら Agent のミスは往々にして隠蔽されているからです。文法上は問題なく、ロジックも通っているように見えても、どこか「違う」。人間なら一目で分かる問題を、Agent は全く意識できないことがあります。
Cursor Rules を設定して自動レビューを行う
Cursor は .cursorrules で Code Review ルールを定義できます。私の設定はこうです:
# .cursorrules (レビュールール部分)
code_review_rules:
# 深刻レベル(修正必須)
critical:
- "コード内にパスワード、APIキーなどの機密情報をハードコードしないこと"
- "データベース操作にはパラメータ化クエリを使用し、SQLインジェクションを防ぐこと"
- "すべての外部入力に対して検証とサニタイズを行うこと"
# 警告レベル(修正を強く推奨)
warning:
- "関数の長さは50行を超えないようにし、分割を検討すること"
- "any 型の使用を避け、可能な限り型定義を明確にすること"
- "非同期操作には try-catch または .catch() でのエラー処理を必須とすること"
# 通知レベル(最適化の提案)
info:
- "単体テストの追加を検討すること"
- "複雑なロジックにはコメントを追加すること"
- "重複コードは共通関数として抽出することを推奨"これを設定した後、Agent がタスクを完了するたびに自己レビューさせます:
タスクが完了しました。現在 .cursorrules 内の code_review_rules に従ってコードをレビューし、
すべての critical および warning レベルの問題をリストアップしてください。Agent は素直に問題をリストアップします。面白いことに、多くの場合、自分で書いたコードでも自己レビューさせると問題を発見できます。これは Agent に「別の視点」でコードを見直させることになります。
人間と機械の結合レビュー戦略
Agent のレビューに完全に依存するのは危険ですし、完全に手動レビューするのは大変です。現在の私は階層的に処理しています:
- Agent 一次レビュー(自動):明らかな構文エラー、コード規範の問題をチェック
- 人間による重点レビュー:以下の点に注目
- ビジネスロジックが正しいか(Agent が最も間違えやすい)
- 境界条件の処理が完全か
- パフォーマンスへの影響(N+1問題などが発生しないか)
- セキュリティリスク(SQLインジェクション、XSSなど)
- テスト検証:テストケースを実行し、既存機能を破壊していないか確認
重要なのは一行ずつレビューしないことです。それは時間の無駄です。核心的なロジックとリスクポイントを掴み、他の詳細はツールとテストに任せましょう。
統計を取ったところ、大規模プロジェクトにおいて Agent が修正したコードの約15-20%に問題がありました。内訳は:
- 5%は深刻なバグ(ロジックエラー、セキュリティ問題)
- 10%はコード品質問題(パフォーマンス、保守性)
- 5%は「動くがプロジェクト規範に合わない」
レビューをしなければ、これらの問題は後の数週間で徐々に露呈し、その時のトラブルシューティングコストは遥かに高くなります。
テクニック7:Git は最後の保険
非常に基本的なことですが、多くの人が軽視しています。
git diff の活用
Agent がコードを修正した後、最初にすることはテスト実行ではなく、これです:
git diff具体的にどのファイルが修正され、各ファイルがどう変わったかを見ます。毎回必ず目を通し、以下に注目します:
- 変更量が予想通りか(数十ファイル変更されていたら警戒すべきです)
- 無関係なファイルが修正されていないか
- 重要なロジックが変更されていないか
小技ですが、git diff --stat でまず変更統計を見てから、詳細な diff を見るかどうか決めると良いです:
git diff --stat
# 出力例:
# src/api/auth.ts | 25 +++++---
# src/models/User.ts | 12 ++--
# src/utils/password.ts | 3 +-
# src/config/database.ts | 150 ++++++++++++++++++++++++++++++++++++++++++++++もしあるファイルが150行増えていて、タスク要件にそのファイルの修正が含まれていない場合…すぐに何が起きたか確認してください。
Checkpoint と Git の連携
前述の Checkpoint と Git を組み合わせて使うと、二重の保険になります:
1. タスク開始前:
- git checkout -b feature/xxx (新ブランチ作成)
- Cursor Checkpoint 作成
2. Agent 完了後:
- git diff (変更チェック)
- テスト実行
- OKなら:git commit
- NGなら:
- 小さな問題:手動修正または Agent に修正させる
- 大きな問題:Checkpoint ロールバックまたは git reset --hard
3. 問題なし確認後:
- git push
- Pull Request 作成このフローのメリットは:
- Checkpoint:高速ロールバック、Git 履歴を汚さない
- Git ブランチ:変更の隔離、メインブランチに影響しない
- Commit 履歴:各ステップの変更記録が残る
私の習慣として、Agent にタスクを行わせるたびに、commit message に注記します:
git commit -m "feat: ユーザー登録機能追加 (by AI Agent)"こうすれば後で問題が起きたとき、commit を見れば Agent が書いたコードだと分かり、調査時に特に注意深く見ることができます。
結論
冒頭の深夜1時のシーンに戻りましょう。
今、Cursor Agent を使ってログインモジュールをリファクタリングするなら、私はこうします:
- コンテキスト管理:認証モジュール用の .cursorrules を作成し、関連ルールのみロード。@ で5つの重要ファイルを引用し、Agent に「この5ファイルのみ修正」と明示する
- タスク分割:全機能を一気にリファクタリングせず、まず基本ログインフローを実装し、動くことを確認してから検証を追加し、最後にキャッシュを最適化する
- コードレビュー:小タスク完了ごとに git diff で変更を確認し、テストを実行し、問題ないことを確認してから次へ進む
こうすることで、Agent がファイルを見つけられない確率は50%から10%未満に、修正ミスをする確率は30%から5%以下に下がります。私が費やす追加時間は、各タスクにつき5〜10分程度です。
正直なところ、AI プログラミングツールは万能ではありません。あなたの代わりにアーキテクチャ設計はできませんし、ビジネスロジックを理解することも、コード品質の責任を負うこともできません。しかし正しく使えば、確実に開発効率を倍増させてくれます——ただし、あなたがそれをどう「管理」するかを学ぶことが前提です。
コンテキスト管理、タスク分割、コードレビュー——この3つの次元はどれも欠かせません。コンテキスト管理は Agent に「正しく見せ」、タスク分割は Agent に「正しく行わせ」、コードレビューはあなたを「安心させ」ます。
最後にアドバイスです。もし今 Cursor Agent で大規模プロジェクトを開発しているなら、今日10分だけ時間を使って Project Rules 設定を確認してみてください。always モードを auto + glob マッチングに変えるだけで、大量のトークンを節約でき、Agent のパフォーマンスが即座にワンランクアップします。
技術は進歩し、ツールは進化しますが、いくつかの原則は変わりません。要件の明確化、タスクの分割、継続的な検証。この方法論は AI プログラミングだけでなく、あらゆる複雑なプロジェクト開発に適用できます。
あなたは Cursor Agent を使う中で、どんな落とし穴に遭遇しましたか?コメント欄で経験をシェアしてください。
Cursor Agent 大規模プロジェクト開発完全フロー
タスク開始から最終確認までの完全なワークフロー。大規模プロジェクトで Agent が効率的かつ確実に動作することを保証します
⏱️ Estimated time: 30 min
- 1
Step1: タスク準備:コンテキストとチェックポイントの設定
コンテキスト管理は成功の鍵です。タスク開始前に必ず準備作業を行います:
Git ブランチ管理:
• git checkout -b feature/xxx(新ブランチ作成で変更を隔離)
• git status(現在のブランチ状態確認)
Checkpoint 作成:
• Cmd/Ctrl + Shift + P を押す
• "Create Checkpoint" を入力
• メモを追加:XXモジュールリファクタリング前
Project Rules 最適化:
• .cursorrules 設定を確認
• always ではなく auto + glob モードを使用しているか確認
• 現在のタスクに関連するルールのみ保持
ファイル範囲の明確化:
• 修正が必要なすべての重要ファイルをリストアップ
• @ 構文でこれらのファイルを引用する準備
• どのファイル/ディレクトリを修正してはいけないか明確化 - 2
Step2: タスク実行:Agent 作業範囲の精密な制御
タスク実行段階では Agent の作業範囲を精密に制御し、見落としや誤修正を防ぎます:
Long Context 有効化(複雑なタスク):
• Cursor 設定を開く
• Long Context モードを有効化
• 注意:単純なタスクではオフにしてトークン浪費を防ぐ
@ 構文による重要ファイルの引用:
• すべての関連ファイルを明確にリストアップ
• 例:"ユーザー認証フローのリファクタリングをお願いします。以下のファイルが関係します:
@src/routes/auth.ts (認証ルート)
@src/middleware/jwt.ts (JWTミドルウェア)
@src/models/User.ts (ユーザーモデル)"
修正範囲の限定:
• 修正可能なディレクトリ範囲を明確化
• 例:"修正可能:src/api/** 配下の全ファイル"
• 禁止する修正範囲を明確化
• 例:"修正不可:src/api/legacy/** (これは古いコード)"
• 最後に一言:"他のファイルは修正しないでください"
職責によるタスク分割(縦方向分割):
• ファイルごとの横方向分割(フロント→バック→DB)はしない
• 機能ごとの縦方向分割を行う(基本機能→検証強化→体験最適化)
• 各タスクは完全な機能ポイントであり、独立してテスト可能にする - 3
Step3: コードレビュー:多層的な変更チェック
Agent がタスクを完了した後、多層的なレビューを経てコミットを確認します:
git diff による変更チェック:
• まず git diff --stat で変更統計を確認
• 変更ファイル数が予想範囲内か確認
• あるファイルの行数が大幅に増えていたら原因を確認
• git diff で詳細な変更を確認
• 重点項目:無関係なファイルが修正されていないか、重要ロジックが変更されていないか
Agent 自己レビュー:
• Agent に .cursorrules 内の code_review_rules に従って自己チェックさせる
• コマンド:"タスクが完了しました。現在 .cursorrules 内の code_review_rules に従ってコードをレビューし、すべての critical および warning レベルの問題をリストアップしてください"
• Agent がリストアップした問題を一つずつ確認して修正
人間による重点レビュー(一行ずつ見ない):
• ビジネスロジックの正しさ(Agent が最も間違えやすい)
• 境界条件の処理(空値、異常系など)
• パフォーマンスへの影響(N+1クエリ、メモリリークなど)
• セキュリティリスク(SQLインジェクション、XSS、機密情報漏洩など)
テスト実行:
• npm test または pytest で全テスト実行
• 既存機能を破壊していないか確認
• 新機能がある場合、テストカバレッジを確認 - 4
Step4: 決定とコミット:テスト合格後のコードコミット
レビューとテスト結果に基づき、次の操作を決定します:
テスト合格の場合:
• git add .(全変更をステージング)
• git commit -m "feat: XX機能追加 (by AI Agent)"
• 注意:commit message に Agent 生成コードであることを明記
• Cursor Checkpoint 削除(ロールバック不要のため)
テスト失敗または問題発見の場合:
• 小さな問題(局所的なロジックエラー):
- 手動修正
- または Agent に個別修正させる:"@src/auth.ts の XX 問題を修正して"
• 大きな問題(方向性の誤り、アーキテクチャ破壊):
- Checkpoint ロールバック(全変更を即座に取り消し)
- または git reset --hard(完全取り消し)
- タスク分割方法を再考
- コンテキスト範囲を調整して再開
境界ケース(問題があるか不明):
• 一時的な commit を作成して現状保存
• テスト環境で検証
• 検証結果に基づき継続するか判断 - 5
Step5: 最終確認:コードプッシュと PR 作成
すべての変更に間違いがないことを確認し、リモートリポジトリにプッシュして Pull Request を作成:
コードプッシュ:
• git push origin feature/xxx
• 初回プッシュの場合:git push -u origin feature/xxx
Pull Request 作成:
• GitHub/GitLab 上で PR 作成
• PR タイトル:簡潔に機能を記述(例:"ユーザー登録機能追加")
• PR 説明:以下を含める
- 実装機能の概要
- 主な変更点
- テスト状況
- 注記:"本 PR の一部コードは AI Agent により生成され、人工レビュー済み"
Code Review 待ち:
• チームメンバーによる Code Review
• フィードバックに基づき修正
• 修正後、「コードレビュー」と「決定とコミット」フローを繰り返す
マージ後のクリーンアップ:
• PR マージ後、リモートブランチ削除
• git checkout main && git pull
• git branch -d feature/xxx(ローカルブランチ削除)
FAQ
Project Rules の設定で、なぜ always モードではなく auto + glob モードを使うのですか?
auto + glob モードを使用するメリット:
• Agent は対応するコードを修正するときのみ関連ルールをロードします(例:フロントエンドコード修正時のみフロントエンドルールをロード)
• トークン使用量を70%削減可能
• Agent が無関係なルールに妨害されず、現在のタスクに集中できる
• 設定例:type: auto, glob: "src/frontend/**/*.{ts,tsx}"
実測効果:中規模プロジェクトにおいて、auto モードに変更後、Agent の応答速度が50%向上し、タスク要件の理解もより正確になりました。
職責によるタスク分割とファイルによるタスク分割、何が違い、なぜ前者を推奨するのですか?
• フロントエンド→バックエンド→データベースの順で書くと、
• フロントエンド記述時にバックエンドインターフェースが不明で推測になる
• バックエンド記述時にフロントエンドのパラメータ間違いが発覚し戻る
• データベースモデル設計が不合理だと前後両方を修正し直す
• 手戻りが多く、かえって効率が悪い
職責による分割(縦方向分割)の利点:
• 各タスクが完全な機能ポイント(フロント+バック+DB)になる
• 例:タスク1で基本登録フロー、タスク2で検証強化、タスク3で体験最適化
• タスク1完了時点で動かしてテストでき、全機能完成を待つ必要がない
• 前後端を一緒に作るため、インターフェースの問題をその場で発見できる
• Agent がタスク目標を理解しやすく、混同しない
実測データ:職責による分割方式を使用すると、Agent の一回成功率は60%から85%に向上しました。
Cursor Checkpoint と Git ブランチの違いは何ですか?どちらを使うべきですか?
Cursor Checkpoint の特徴:
• 高速な作成とロールバック、Git 履歴を扱わなくて済む
• 実験的な変更や不確実なタスクに適している
• ロールバック後、すべての変更は即座に取り消され、痕跡が残らない
• 欠点:Checkpoint はリモートにプッシュされず、ローカルにのみ存在する
Git ブランチの特徴:
• 変更を隔離し、メインブランチに影響を与えない
• 完全な commit 履歴を残し、追跡可能
• リモートにプッシュでき、チーム協業に便利
• ロールバックには git reset や git revert が必要
推奨する組み合わせ:
1. タスク開始前:Git ブランチ作成(変更隔離)+ Checkpoint 作成(高速ロールバック用)
2. Agent 完了後:小さな問題は Checkpoint ロールバック、大きな問題は git reset --hard
3. テスト合格後:git commit(履歴保存)、Checkpoint 削除(不要になるため)
これにより、Checkpoint の高速ロールバック能力と Git のバージョン管理の利点を両立できます。
タスクで Long Context モードをオンにすべきか、どう判断しますか?
Long Context に適したシーン:
• モジュール間リファクタリング(5ファイル以上関わる場合)
• 複雑な機能開発(複数モジュールの相互作用を理解する必要がある場合)
• 複数ファイルに関わるバグ修正
• パフォーマンス最適化で呼び出しチェーンを確認する場合
オンにすべきでないシーン:
• 単一の関数やコンポーネントの修正
• 単純なバグ修正(1-2ファイルのみ関わる)
• コメントやドキュメントの追加
• コードフォーマット
判断基準:
• 関与ファイル数 ≤ 3:オフ
• 関与ファイル数 4-6:複雑さに応じて決定
• 関与ファイル数 ≥ 7:オンにし、かつ手動で @ を使って重要ファイルを引用
実用テクニック:不確かな場合、まずはオフにして Agent の様子を見ます。もし重要ファイルを見つけられなかったり理解が不十分であれば、Long Context をオンにして再実行します。
Agent が修正したコードにはどのくらい問題がありますか?どのような問題が一般的ですか?
問題の内訳:
• 5% は深刻なバグ(ロジックエラー、セキュリティ脆弱性、データ損失リスク)
• 10% はコード品質問題(低パフォーマンス、保守性欠如、重複コード)
• 5% は「動くがプロジェクト規範に不適合」(命名規則違反、コメント欠如など)
最も一般的な問題タイプ:
1. ビジネスロジックの理解ミス(最も多い)
- Agent が文字通り実装し、暗黙のビジネスルールを無視する
- 例:「ユーザー削除」を論理削除ではなく物理削除で実装してしまう
2. 境界条件の処理不備
- 空値、異常系、同時実行競合などの特殊状況
3. パフォーマンス問題
- N+1クエリ、メモリリーク、全量データロードなど
4. セキュリティリスク
- SQLインジェクション、XSS、機密情報漏洩、権限チェック漏れ
対策:
• Agent のコードを完全に信頼せず、必ず Code Review を行う
• 重点的にビジネスロジック、境界条件、パフォーマンス、セキュリティをレビューする
• 自動レビュールール(.cursorrules の code_review_rules)を確立する
• Agent にタスク完了後、提出前に自己レビューさせる
問題発見後:小さな問題は手動修正または Agent に個別修正させ、大きな問題は直接ロールバックしてやり直します。
Agent が修正すべきでないファイルを修正するのをどう防げばよいですか?
修正範囲の明確な限定:
• タスク記述の最後に一言追加:「他のファイルは修正しないでください」
• 実測:この一言を加えるだけで、無関係なコードを修正する確率が 30% から 5% 以下に下がりました
ホワイトリスト + ブラックリストの使用:
• 修正可能な範囲を明示:「修正可能:src/api/** 配下の全ファイル」
• 修正禁止範囲を明示:「修正不可:src/api/legacy/** (これは古いコード)」
• 自由度を与えつつ、触れてはいけないものを防げます
@ 構文による重要ファイルの引用:
• 修正が必要なすべてのファイルを明確にリストアップ
• 例:「以下のファイルが関係します:@src/routes/auth.ts, @src/middleware/jwt.ts」
• Agent はこれらのファイルを優先的に注目し、誤って他のファイルを修正する確率が減ります
git diff によるタイムリーな発見:
• Agent 完了後すぐに git diff --stat を実行
• 変更ファイルリストが予想通りかチェック
• 無関係なファイルが修正されていたら、即座にロールバックまたは手動復元
.cursorrules の設定:
• ルール追加:「明示的な承認なしに、コアモジュールのコードを修正しないこと」
• 重要ディレクトリに修正禁止理由のコメントを追加
これらの方法を組み合わせることで、Agent によるファイル誤修正の確率を最小限に抑えられます。
テスト駆動開発(TDD)はどのように Agent のタスク遂行を助けますか?
従来方式の問題点:
• Agent が機能を実装した後、正しく理解しているか分からない
• すでに十数ファイルを修正した後で、方向性の誤りに気づく
• 手戻りコストが高く、他の機能を破壊している可能性もある
TDD の利点:
• テストケースが期待する動作を定義するため、Agent に明確な目標がある
• Agent は「テストをパスさせる」ことに集中し、無限に発散しない
• テスト失敗で即座に問題を発見し、損害を最小限に抑えられる
• テスト自体がドキュメントとなり、将来のコード保守時に一目瞭然
具体的なワークフロー:
1. テストケースを手動で書く(または Agent に書かせ、人間がレビューする)
2. テストを実行し、失敗を確認(機能未実装のため)
3. Agent に機能実装させる:「@test/xxx.test.ts 内のテストが通るように XX 機能を実装して」
4. Agent 完了後にテスト実行:合格→コミット、失敗→コードチェックまたはロールバック
実際のケース:
• TDD で認証モジュールをリファクタリングした際、Agent は7回で完了し、方向性の逸脱なし
• テストなしの場合は、同じタスクで十数回試行してもバグが出ていた
重要なポイント:テストケースの品質が Agent のパフォーマンスを決定します。テストが良ければ Agent は正確に実装できますが、曖昧だと Agent は当てずっぽうになります。
9 min read · 公開日: 2026年1月10日 · 更新日: 2026年3月22日
関連記事
AI コード生成のミスを減らす?この5つの Prompt テクニックで効率50%アップ

AI コード生成のミスを減らす?この5つの Prompt テクニックで効率50%アップ
Cursor 上級テクニック:開発効率を倍増させる10の実践的手法(2026年版)

Cursor 上級テクニック:開発効率を倍増させる10の実践的手法(2026年版)
Cursor バグ修正完全ガイド:エラー分析から解決策検証までの効率的ワークフロー

コメント
GitHubアカウントでログインしてコメントできます