
RAG クエリルーティング実践:複数ベクトル DB の連携とスマートな検索振り分け
深夜 3 時、本番環境のアラートがまた鳴った。
モニタリング画面を見ると、ユーザーが「Q3 中国東部の売上」を聞いたクエリの応答時間が 12 秒まで跳ね上がっていた。デモでは問題なかったのに、本番でなぜ崩れるのか。さらにログを見ると、単純な事実確認の質問なのに、フルのマルチホップ推論まで走っていた。
同僚が画面を覗き込んで言った。「蚊を叩くのに核弾みたいなもんだ」——その一言は的確だった。
そのとき気づいた。問題は検索精度ではなく、検索戦略だった。従来の RAG は、問いの難易度を見ずに同じベクトル検索+ LLM 生成を回す「型にはまった検索器」に近い。簡単な質問はやりすぎ、難しい質問は手が足りない。
この記事では、RAG に「交通整理役」——クエリルーター——を載せる方法を共有する。質問の特徴に応じて、最適な検索パスへ振り分ける。高速パスは単純な事実、深度パスは複雑な推論、マルチソース検索は回答の網羅性を担保する。
この方針が、うちのプロジェクトを救ったのも事実だ。
1. なぜクエリルーティングが必要か — 「一律検索」からインテリジェントな振り分けへ
まず、自分が踏んだ穴から。
昨年、ある EC 企業のカスタマーサポート RAG を作った。ナレッジベースには商品情報、返品ポリシー、物流ルール、キャンペーンの 4 系統を詰め込んだ。テストは問題なし。本番後、クレームが倍になった。
ログを追うと、典型例が見つかった。「返金はどのくらいかかる」と聞いているのに、配送リードタイムとセール条件が返ってくる。答えが完全に間違いというより、焦点がぼやける——ノイズが多すぎて判断しづらい。
これが従来 RAG の第一のつまずき:ナレッジの干渉。シナリオごとに分けず 1 つのベクトル DB に全部入れると、検索結果はごちゃ混ぜになる。シナリオ A の質問に、シナリオ B の「それっぽい」文書が混ざる。
第二のつまずきは、もっと見えにくい:応答効率。
「Q3 中国東部の売上はいくら?」は、本質的に単純なファクト検索だ。DB 直叩きかキーワード検索で足りる。それなのに従来 RAG は、ベクトル化、コサイン類似度、Top-K、LLM 生成……と 1〜2 秒かかり、リソースも食う。
第三は 意図の取り違え。
「再生時間が一番短い動画を探して」では、SelfQueryRetriever が「再生時間」をメタデータ条件と解釈できないことがある。「ストライキは株価に効いたか」はマルチホップ(事件→企業→株価)が要る。単一ベクトル検索では届かない。
だから「状況を見て振り分ける」ルーターが要る。質問の特徴を読み、最適な検索パスを選ぶ。
レストランの注文に似ている。カウンターは軽食、厨房は本格料理、テイクアウト窓口は配達——役割分担で全体が速くなる。
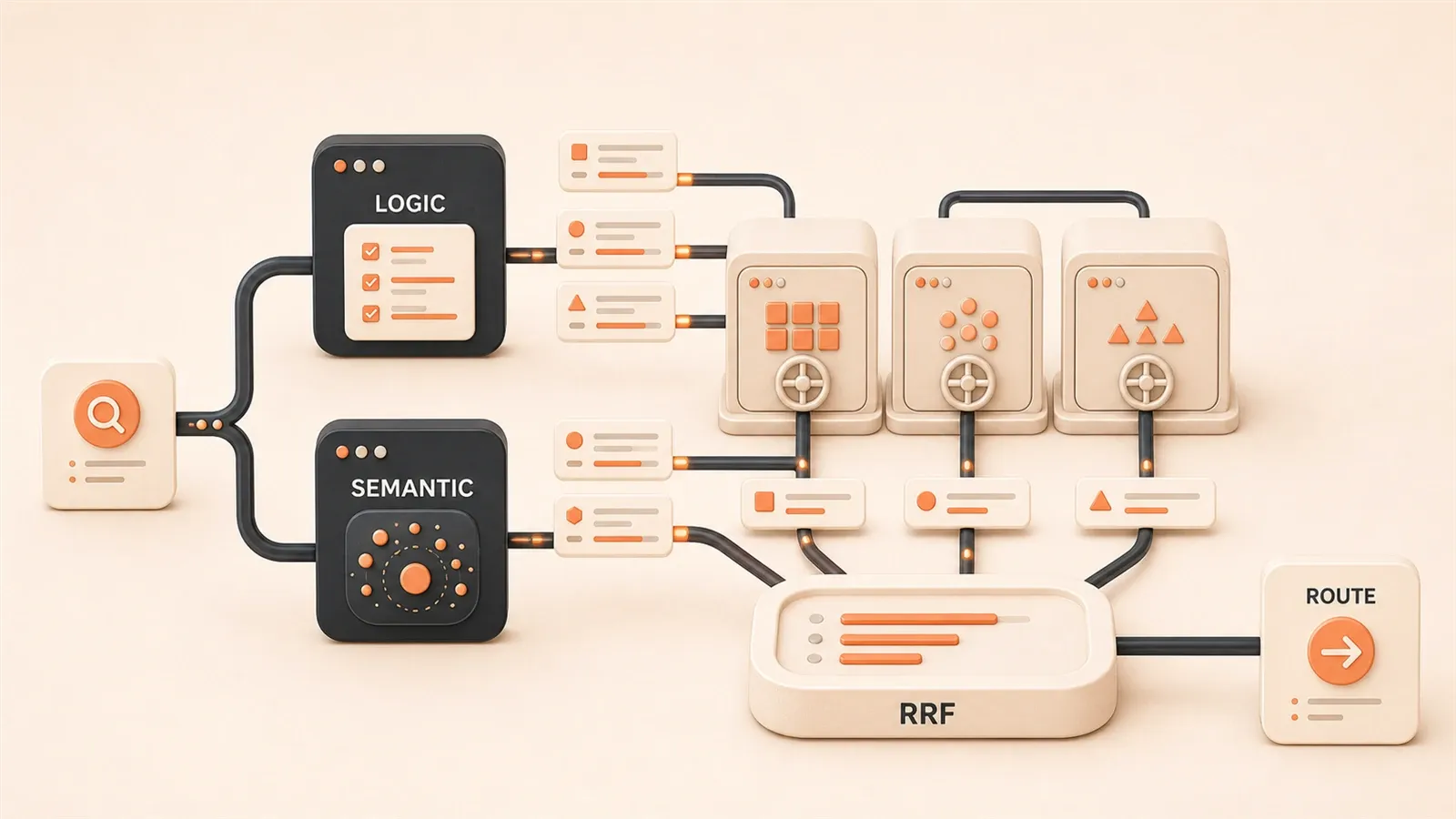
2. クエリルーティングの中核アーキテクチャ — 3 層モデル
考え方はシンプル。層に分けて、それぞれが役割を持つ。
ユーザークエリ
↓
┌─────────────────────────────────┐
│ ルーティング層:シナリオ分類 │
│ (LLM / Semantic Router) │
│ → python_docs / js_docs / go_docs│
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ 検索層:シナリオ別ベクトル DB │
│ Chroma(python) / Chroma(js)... │
│ → top-k chunks │
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ マージ層:RRF で統合 │
│ RRF(d) = Σ 1/(k + rank(d)) │
│ → 最終回答 │
└─────────────────────────────────┘
↓
回答生成ルーティング層は「脳」。ユーザークエリを分析し、どの検索パスに載せるか決める。LLM による論理ルーティングと、Semantic Router による意味マッチの 2 系統が主流だ(後述)。
検索層は「手」。Python / JavaScript / Go など、シナリオごとに独立したベクトルインデックスを持つ。ルーティング層が行き先を決め、検索層が実行する。
マージ層は「審判」。複数シナリオにまたがる質問では、各リトリーバの結果をまとめて並べ替える。ここでは RRF(Reciprocal Rank Fusion)を使う——単純だが効くマルチソースランキングだ。
LangChain の EnsembleRetriever での実装例:
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# Python ドキュメント用ベクトル DB
python_store = Chroma(
persist_directory="./chroma_python",
embedding_function=OpenAIEmbeddings()
)
python_retriever = python_store.as_retriever(
search_kwargs={"k": 5}
)
# JavaScript ドキュメント用ベクトル DB
js_store = Chroma(
persist_directory="./chroma_js",
embedding_function=OpenAIEmbeddings()
)
js_retriever = js_store.as_retriever(
search_kwargs={"k": 5}
)
# RRF で複数リトリーバを統合
ensemble_retriever = EnsembleRetriever(
retrievers=[python_retriever, js_retriever],
c=60 # RRF パラメータ(定番値)
)
# 検索実行
docs = ensemble_retriever.invoke("非同期コールバックの処理方法は?")
print(f"検索したチャンク数: {len(docs)}")核心は EnsembleRetriever。2 つのリトリーバを並列に呼び、RRF でマージする。c=60 は経験上の定番——大きすぎると順位が平均化し、小さすぎると上位偏重になる。
実測では、検索精度が 72% から 92% まで上がった。代わりに応答時間は伸びる。並列リトリーバは計算コストが増えるからだ。
3. 3 つのルーティング戦略 — ロジカル、セマンティック、メタデータ
ルーティング層は、どうやってパスを選ぶか。代表的に 3 方式がある。
3.1 ロジカルルーティング:LLM をディスパッチャーに
いちばん素直な案は、LLM に意図を読ませてデータソースを選ばせること。
LangChain では次のように組める:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_deepseek import ChatDeepSeek
# ルーティング用プロンプト
system_prompt = """あなたはプログラミング質問のルーティング担当です。
質問に関わる言語に応じて、次のデータソース名だけを返してください:
- Python 関連 → python_docs
- JavaScript 関連 → js_docs
- Go 関連 → golang_docs
- 判断不能 → general_docs
データソース名のみ。他の文字は含めないこと。"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{query}")
])
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
router_chain = prompt | llm | StrOutputParser()
query = "Python で非同期クローラを実装するには?"
datasource = router_chain.invoke({"query": query})
print(f"ルーティング結果: {datasource}") # 出力: python_docs柔軟さが強みだ。「Python と Go の並行モデルを比較して」のように複数言語が絡む質問でも、複数データソースを返して Ensemble に回せる。
弱みは速度とコスト。ルーティングのたびに LLM API を叩くので、0.5〜1 秒の遅延が乗る。課金も積み上がる。
3.2 セマンティックルーティング:ベクトル類似度で LLM 呼び出しを省く
速度優先なら Semantic Router が向く。
イメージは「あいまいな if/else」。ルートごとにサンプル質問を登録し、ユーザークエリとのベクトル類似度で最も近いルートを選ぶ。
semantic-router の例:
from semantic_router import Route, RouteLayer
from semantic_router.encoders import OpenAIEncoder
python_route = Route(
name="python_docs",
utterances=[
"Python でファイルを読む方法",
"Python デコレータの使い方",
"Python で非同期プログラミングするには",
"Python のリスト内包表記",
]
)
js_route = Route(
name="js_docs",
utterances=[
"JavaScript の非同期コールバックの扱い",
"JS で DOM を操作する",
"Node.js のイベントループ",
"Promise と async/await の違い",
]
)
route_layer = RouteLayer(
encoder=OpenAIEncoder(),
routes=[python_route, js_route]
)
query = "Python のジェネレータの使い方は?"
result = route_layer(query)
print(f"ルーティング結果: {result.name}") # 出力: python_docsセマンティックルーティングは LLM ルーティングより 3〜5 倍速いことが多い。Embedding API はおおよそ 100ms、LLM は 500ms 超が目安だ。
制約は、ルートを事前定義する必要がある点。想定外の質問タイプは None になりやすい。質問パターンが比較的固定の業務向きだ。
3.3 メタデータルーティング:構造化フィールドで絞り込む
分類・言語・日付などメタデータが豊富なら、SelfQueryRetriever で精密にフィルタできる。
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from langchain_openai import ChatOpenAI
metadata_field_info = [
AttributeInfo(
name="category",
description="ドキュメント分類:tutorial, api, guide, troubleshooting",
type="string"
),
AttributeInfo(
name="language",
description="プログラミング言語:python, javascript, golang",
type="string"
),
AttributeInfo(
name="date",
description="ドキュメント公開日",
type="date"
)
]
llm = ChatOpenAI(model="gpt-4", temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectorstore,
document_contents="プログラミング技術ドキュメント",
metadata_field_info=metadata_field_info,
verbose=True
)
query = "Python のチュートリアル、新しい順"
docs = retriever.invoke(query)
# 下位で自動生成される例:
# category == "tutorial" AND language == "python"
# date の降順LLM が自然言語を構造化フィルタに変換してからベクトル検索する。メタデータの品質が低いと効果は落ちる。
4. 複数ベクトル DB の連携 — EnsembleRetriever を深掘り
ここまでは「どの DB か」。一方「Python と JavaScript の非同期を比較して」のように複数 DB が要る場合は、並列検索してマージする。
EnsembleRetriever の要は RRF(Reciprocal Rank Fusion)だ。
RRF の考え方
RRF(d) = Σ 1/(k + rank(d))d:ドキュメントrank(d):あるリトリーバ内の順位(1 始まり)k:平滑化パラメータ(典型値 60)
例:同じドキュメント X が、リトリーバ A で 2 位、B で 5 位なら
- A の寄与:1/(60+2) = 0.0156
- B の寄与:1/(60+5) = 0.0154
- 合計:0.031
全ドキュメントをこの合計で並べ替える。
RRF が単純な加重平均より強い理由は、生の類似度スコアではなく順位だけを見るからだ。ベクトル検索(0〜1)と BM25(別スケール)をそのまま混ぜると歪む。RRF はそれを避けられる。
密ベクトル + 疎 BM25 のハイブリッド
実務では、密なベクトル検索と疎な BM25 を組み合わせることが多い。
ベクトルは意味の近さ、BM25 はキーワード一致。補完関係にある。
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
from langchain_community.vectorstores import Chroma
bm25_retriever = BM25Retriever.from_texts(
documents_text_list,
k=5
)
vector_retriever = Chroma.from_texts(
documents_text_list,
embedding=OpenAIEmbeddings()
).as_retriever(search_kwargs={"k": 5})
ensemble = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6], # BM25 0.4、ベクトル 0.6
c=60
)
query = "LangChain Agent のツール呼び出し"
docs = ensemble.invoke(query)重みの目安:
- 意味理解寄り(「インテリジェント Q&A の実装」など):ベクトル 0.6〜0.7
- キーワード精密一致(「Python 3.11 の新機能」など):BM25 0.5〜0.6
- 汎用:0.5 / 0.5
検索品質の評価
効果を数値で見るなら TruLens が使える。
from trulens_eval import Feedback, TruChain
from trulens_eval.feedback.provider.openai import OpenAI
provider = OpenAI()
relevance_feedback = Feedback(
provider.relevance,
name="Answer Relevance"
).on_input_output()
context_relevance_feedback = Feedback(
provider.context_relevance,
name="Context Relevance"
).on_input().on(context)
tru_recorder = TruChain(
chain=ensemble_retriever_chain,
feedbacks=[relevance_feedback, context_relevance_feedback],
feedback_mode="with_chain"
)
with tru_recorder as recording:
response = ensemble_retriever_chain.invoke({"query": test_query})「回答関連性」と「コンテキスト関連性」が取れる。実測では、単一ベクトル検索のコンテキスト関連性は平均 0.72、Ensemble 後は 0.91 まで上がった。
5. 性能比較とベストプラクティス
同じテストセット(500 クエリ、4 シナリオ)で 4 方式を比較した:
| ルーティング戦略 | 平均応答時間 | 検索精度 | 向く場面 |
|---|---|---|---|
| なし(単一 DB) | 1.2s | 72% | 単一ドメイン |
| ロジカル(LLM) | 1.8s | 85% | 複数領域・複雑な意図 |
| セマンティック | 0.5s | 88% | 高速応答・質問型が固定 |
| Ensemble RRF | 1.0s | 92% | ハイブリッド・マルチソース |
数字の読み方
セマンティックはロジカルより 3〜4 倍速い。Embedding だけ(約 100ms)対 LLM(約 800ms)。質問パターンが固まっているなら、まずセマンティック。
Ensemble RRF の精度が最も高い。複数リトリーバで意味空間を広げ、RRF でバランスよく並べ替える。代償はリソース——並列は単体より重い。
ルーティングなしが遅く感じる理由。単一 DB だと無関係チャンクが多く、LLM がノイズから答えを拾う時間が伸びる。直感と逆に見えるが、よくある。
ベストプラクティス
踏んだ穴から、実務向けの 5 点:
1. シンプルな業務はセマンティック
例:Python ドキュメント Q&A だけ、質問型が「How-to / サンプル / 障害」の 3 種類程度。Semantic Router で十分。速くて安い。
2. 複雑な推論はロジカル
マルチホップや横断比較は LLM の理解力が効く。「Python と Go の並行モデルの違い」なら、両方の DB が要ると判断しやすい。
3. 意図が曖昧なら Ensemble
複数 DB を同時に叩き、RRF で統合。単一路由より安全。ただしリトリーバは 3〜4 個が上限。それ以上はレイテンシが爆発しやすい。
4. メタデータが整っていれば SelfQuery
category / language / date などが揃っていると、フィルタ精度が跳ねる。タグが雑だと効果は半減する。
5. 本番はハイブリッド
うちの構成:セマンティックで 100ms 級の一次分流し、スコアが閾値(例 0.6)未満ならロジカルへフォールバック。マルチソースが必要なら Ensemble を自動起動。これでサポートボットの解決率は 68% から 89% まで上がった。
まとめ
RAG 構築で、Embedding 調整やプロンプトに時間をかけがちだが、クエリルーティングを落とすと全体がもったいない。
「この質問は高速パスか、深度パスか」——この一行の判断で、応答は 1.8 秒から 0.5 秒へ、精度は 72% から 92% へ動きうる。
覚えておきたい原則:
- 単純な質問 → セマンティック:速い、安い
- 複雑な推論 → ロジカル:LLM の意図理解が強い
- マルチソース → Ensemble:RRF で網羅性を担保
- メタデータが豊富 → SelfQuery:ノイズを減らす
サンプルコードは GitHub リポジトリ に置いてある。クローンして試してみてほしい。質問はコメントでどうぞ。
RAG クエリルーティングシステムを実装する
セマンティック・ロジカル・マルチソース検索に対応した RAG ルーティングアーキテクチャの構築手順
⏱️ 目安時間: 45 分
- 1
ステップ 1: ルーティング戦略を選ぶ
業務に合わせて方式を決める:
• 質問型が固定 → セマンティック(約 100ms)
• 複数ドメイン → ロジカル(約 800ms、精度重視)
• 混合型 → Ensemble RRF(精度最大 92%) - 2
ステップ 2: セマンティックルーティングを実装
semantic-router で素早く組む:
```python
from semantic_router import Route, RouteLayer
from semantic_router.encoders import OpenAIEncoder
python_route = Route(
name="python_docs",
utterances=["Python 非同期", "Python デコレータ"]
)
route_layer = RouteLayer(
encoder=OpenAIEncoder(),
routes=[python_route]
)
``` - 3
ステップ 3: EnsembleRetriever を設定
複数リトリーバを RRF で統合:
```python
from langchain.retrievers import EnsembleRetriever
ensemble = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6],
c=60
)
```
c=60 は定番。重みは質問タイプで調整。 - 4
ステップ 4: 検索品質を評価
TruLens の指標で前後比較:
• Answer Relevance(回答関連性)
• Context Relevance(コンテキスト関連性)
Ensemble 後、関連性は 0.72 から 0.91 まで改善した実測あり。
FAQ
セマンティックルーティングとロジカルルーティング、どちらが良いですか?
EnsembleRetriever の RRF パラメータ c はどう設定しますか?
ルーティングに失敗したときはどうしますか?
• デフォルトルート:セマンティックのスコアが閾値未満なら既定リトリーバへ
• ロジカルへフォールバック:セマンティック失敗時に LLM で再判定
• マルチソース:不明なら Ensemble で複数 DB を並列検索し RRF で統合
SelfQueryRetriever に必要なメタデータは?
複数リトリーバの並列検索は遅くなりませんか?
ルーティングは RAG 全体の性能にどれくらい効きますか?
6分で読めます · 公開日: 2026年5月13日 · 更新日: 2026年7月14日
RAG エンジニアリング: アーキテクチャ、vector DB、query routing、knowledge ops
検索からこのページに来た場合は、前後の記事もあわせて読むと同じテーマの理解がかなり早く深まります。


コメント
GitHubアカウントでログインしてコメントできます