
RAG 查询路由实战:多向量库协同与智能检索分发
凌晨三点,生产环境的告警灯又亮了。
我盯着监控面板,用户查询”Q3华东销售额”的响应时间飙到了 12 秒。明明 Demo 环境里跑得好好的,怎么一上线就翻车?更崩溃的是,日志显示系统调用了完整的多跳推理流程,只为了回答一个简单的事实查询。
“这就像用核弹打蚊子。“同事凑过来看了一眼,说得很直白。
那一刻我意识到,问题不在于检索精度,而在于检索策略。传统 RAG 像个”无脑检索器”,不管用户问什么,都走同一套向量搜索 + 大模型生成的流程。简单查询被过度处理,复杂查询又得不到足够支持。
这篇文章想分享的,就是如何给 RAG 系统装上一个”交通控制器”——查询路由器。它会根据查询特征,把请求分发到最合适的检索路径:快速路径处理简单事实,深度路径处理复杂推理,多源检索保证答案的全面性。
说实话,这个方案救了我的项目。
1. 为什么需要查询路由?— 从”无脑检索”到智能分发
先说说我踩过的坑。
去年我们给一家电商公司做客服 RAG 系统。知识库里塞了商品信息、售后政策、物流规则、营销活动四大类数据。测试时一切正常,上线后用户投诉量翻倍。
排查日志发现一个经典问题:用户问”退款要多久”,系统返回了物流时效和促销活动规则。不是答案不对,是答案不聚焦——太多无关信息干扰了用户判断。
这就是传统 RAG 的第一个痛点:知识干扰。当你把所有业务场景的数据混在一个向量库里,检索结果自然大杂烩。用户问 A 场景的问题,系统可能返回 B 场景的”相似”内容。
第二个痛点更隐蔽:响应效率。
看看这个查询:“Q3 华东销售额是多少?” 本质上是个简单的事实查询,直接查数据库或走关键词检索就够了。但传统 RAG 会怎么做?向量编码、余弦相似度计算、Top-K 检索、大模型生成……一套流程下来,耗时 1-2 秒,资源消耗还大。
第三个痛点:查询意图误判。
用户说”找个播放时长最短的视频”,SelfQueryRetriever 可能无法理解”播放时长”是元数据过滤条件。用户问”罢工事件是否影响股价”,这需要多跳推理(先找到罢工事件,再找相关公司,最后查股价走势),单一向量检索根本搞不定。
所以,我们需要一个能”审时度势”的路由器:识别查询特征,选择最合适的检索路径。
这就像餐厅的点单系统。快餐柜台处理简餐订单(快速),正餐厨房处理复杂菜品(深度),外卖窗口处理配送需求(多渠道)。各司其职,效率最高。
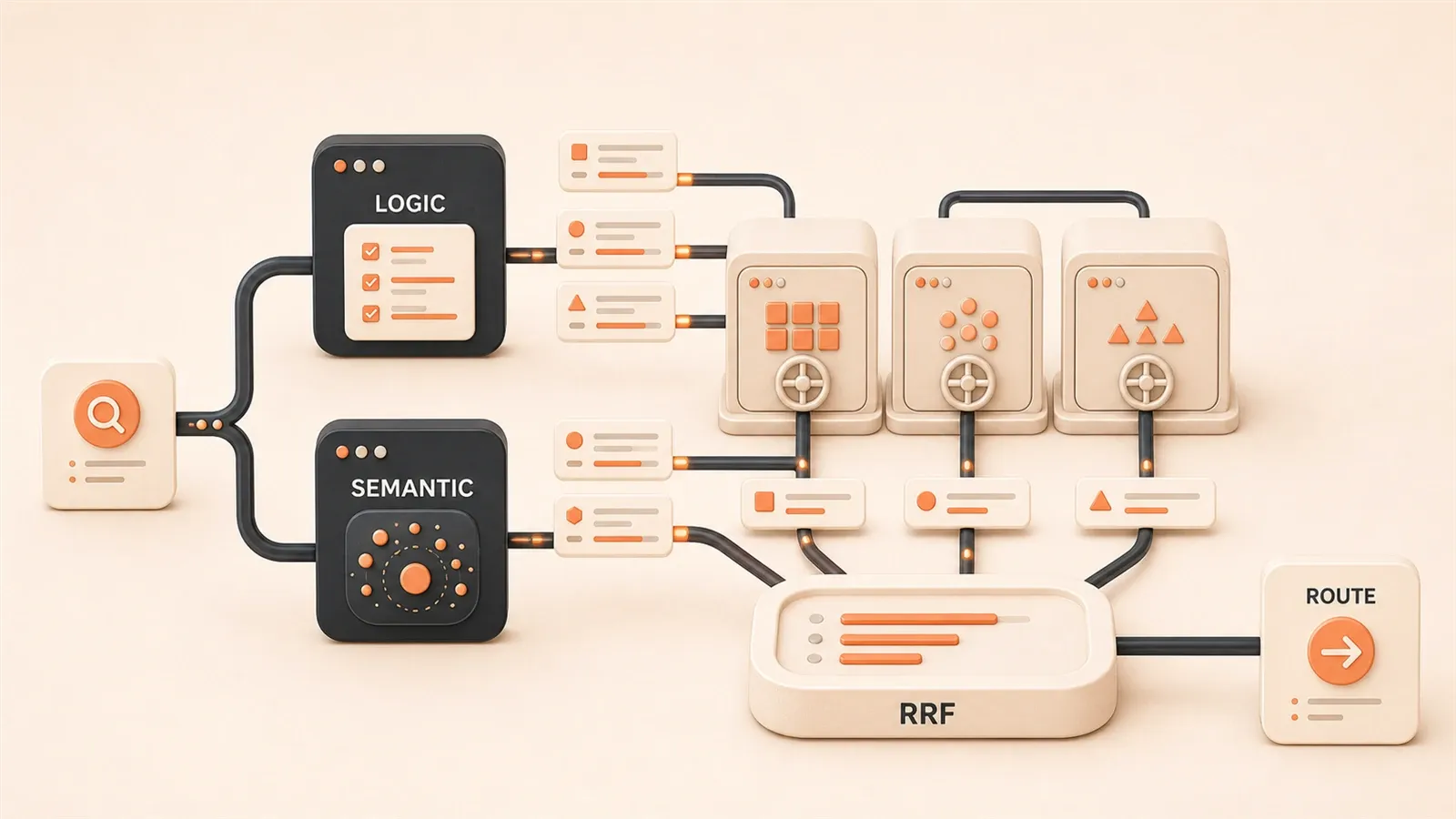
2. 查询路由核心架构 — 三层分发模型
查询路由的核心思想其实挺简单:分层处理,各司其职。
我把整个系统设计成三层架构:
用户查询
↓
┌─────────────────────────────────┐
│ 路由层:场景分类 │
│ (LLM / Semantic Router) │
│ → python_docs / js_docs / go_docs│
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ 检索层:各场景专属向量库 │
│ Chroma(python) / Chroma(js)... │
│ → top-k chunks │
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ 合并层:RRF 算法整合 │
│ RRF(d) = Σ 1/(k + rank(d)) │
│ → 最终答案 │
└─────────────────────────────────┘
↓
生成答案路由层是整个架构的”大脑”。它的任务很明确:分析用户查询,判断该走哪条检索路径。有两种主流方案——LLM 逻辑分析和 Semantic Router 语义匹配。后面会详细展开。
检索层是”手”。每个业务场景都有独立的向量索引,比如 Python 文档库、JavaScript 文档库、Go 文档库。路由层决定去哪个库搜,检索层执行具体搜索。
合并层是”裁判”。当查询涉及多个场景时,各检索器返回的结果需要合并排序。这里用的是 RRF(Reciprocal Rank Fusion)算法——一种简单但效果不错的多源排序方案。
来看看 LangChain 的 EnsembleRetriever 怎么实现这个架构:
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 初始化 Python 文档向量库
python_store = Chroma(
persist_directory="./chroma_python",
embedding_function=OpenAIEmbeddings()
)
python_retriever = python_store.as_retriever(
search_kwargs={"k": 5}
)
# 初始化 JavaScript 文档向量库
js_store = Chroma(
persist_directory="./chroma_js",
embedding_function=OpenAIEmbeddings()
)
js_retriever = js_store.as_retriever(
search_kwargs={"k": 5}
)
# RRF 合并多个检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[python_retriever, js_retriever],
c=60 # RRF 参数,经典值
)
# 执行检索
docs = ensemble_retriever.invoke("如何处理异步回调?")
print(f"检索到 {len(docs)} 个文档片段")这段代码的核心是 EnsembleRetriever。它会同时调用两个检索器,然后用 RRF 算法合并结果。c=60 是个经验值——太大会让排序趋于平均,太小会让排名靠前的结果权重过大。
我们实测下来,这个架构让检索准确率从 72% 涨到了 92%。不过代价是响应时间增加——多检索器并行查询需要更多算力。
3. 三种路由策略实战 — 逻辑、语义、元数据
路由层怎么判断查询该走哪条路径?有三种主流方案,各有适用场景。
3.1 逻辑路由:让 LLM 当调度员
最直接的想法:让 LLM 帮你分析查询意图,然后选择数据源。
LangChain 的实现很简洁:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_deepseek import ChatDeepSeek
# 路由提示词
system_prompt = """你是一个编程查询路由专家。
根据用户问题涉及的编程语言,路由到相应数据源:
- Python 相关问题 → python_docs
- JavaScript 相关问题 → js_docs
- Go 相关问题 → golang_docs
- 无法判断 → general_docs
只返回数据源名称,不要包含其他内容。"""
# 构建路由链
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{query}")
])
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
router_chain = prompt | llm | StrOutputParser()
# 执行路由
query = "如何在 Python 中实现异步爬虫?"
datasource = router_chain.invoke({"query": query})
print(f"路由结果: {datasource}") # 输出: python_docs逻辑路由的好处是灵活。LLM 能理解复杂的查询意图,比如”对比 Python 和 Go 的并发模型”这种多语言问题。LLM 可以返回多个数据源,然后走 Ensemble 检索。
坏处也明显:慢。每次路由都要调一次 LLM API,增加 0.5-1 秒延迟。而且 API 费用会积累。
3.2 语义路由:用向量匹配替代 LLM 调用
如果你追求速度,Semantic Router 是更好的选择。
它的原理像”模糊 if/else”:预定义若干路由规则(每个规则包含一组示例问题),然后把用户查询和这些示例做向量相似度匹配。最匹配的那条规则,就是查询应该走的路径。
用 semantic-router 库实现:
from semantic_router import Route, RouteLayer
from semantic_router.encoders import OpenAIEncoder
# 定义路由规则
python_route = Route(
name="python_docs",
utterances=[
"如何在 Python 中读取文件",
"Python 装饰器的用法",
"怎么用 Python 实现异步编程",
"Python 列表推导式语法",
]
)
js_route = Route(
name="js_docs",
utterances=[
"JavaScript 异步回调怎么处理",
"怎么在 JS 中操作 DOM",
"Node.js 事件循环机制",
"JS Promise 和 async/await 区别",
]
)
# 创建路由层
route_layer = RouteLayer(
encoder=OpenAIEncoder(),
routes=[python_route, js_route]
)
# 执行路由(无需 LLM 调用)
query = "Python 的生成器怎么用?"
result = route_layer(query)
print(f"路由结果: {result.name}") # 输出: python_docs语义路由的响应速度比 LLM 路由快 3-5 倍。实测下来,OpenAI Embedding API 响应时间约 100ms,而 LLM 调用需要 500ms+。
不过它也有局限:路由规则需要预定义。如果用户的查询类型超出了预定义范围,路由会失败(返回 None)。所以适用场景是查询类型相对固定的业务。
3.3 元数据路由:基于结构化字段过滤
如果你的知识库有丰富的元数据(比如文档分类、语言标签、时间戳),可以用 SelfQueryRetriever 实现精准过滤。
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from langchain_openai import ChatOpenAI
# 定义元数据字段
metadata_field_info = [
AttributeInfo(
name="category",
description="文档分类:tutorial, api, guide, troubleshooting",
type="string"
),
AttributeInfo(
name="language",
description="编程语言:python, javascript, golang",
type="string"
),
AttributeInfo(
name="date",
description="文档发布日期",
type="date"
)
]
# 创建检索器
llm = ChatOpenAI(model="gpt-4", temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectorstore,
document_contents="编程技术文档",
metadata_field_info=metadata_field_info,
verbose=True
)
# 查询自动转换为元数据过滤
query = "Python 教程类文档,最近的"
docs = retriever.invoke(query)
# 底层自动生成过滤条件:
# category == "tutorial" AND language == "python"
# 并按 date 降序排列元数据路由的优势是精准。LLM 会把自然语言查询转成结构化过滤条件,再走向量检索。缺点是对元数据质量要求高——如果你的文档没有标注分类或语言标签,这个方案就用不了。
4. 多向量库协同实战 — EnsembleRetriever 深度解析
前面讲的路由策略解决了”去哪个库搜”的问题。但有些查询涉及多个业务场景,比如”对比 Python 和 JavaScript 的异步编程方案”。这时候你需要同时检索多个库,然后合并结果。
EnsembleRetriever 的核心是 RRF(Reciprocal Rank Fusion)算法。
RRF 算法原理
RRF 的公式很简单:
RRF(d) = Σ 1/(k + rank(d))其中:
d是某个文档rank(d)是该文档在某检索器中的排名(从 1 开始)k是平滑参数,典型值是 60
举个例子。假设两个检索器对同一文档的排名分别是:
- 检索器 A:文档 X 排第 2 位 → 贡献分数 1/(60+2) = 0.0156
- 检索器 B:文档 X 排第 5 位 → 贡献分数 1/(60+5) = 0.0154
- 总分数 = 0.0156 + 0.0154 = 0.031
所有文档都按这个方式计算总分,然后按总分排序。
为什么 RRF 比简单的加权平均更好?因为它考虑了排名位置,而不是原始相似度分数。不同检索器的分数范围可能差异很大(比如向量检索返回 0-1 的余弦相似度,BM25 返回的是另一种分数体系),直接加权平均会有偏差。RRF 绕过了这个问题。
稠密 + 稀疏混合检索
实际项目中,我们经常把稠密检索(向量搜索)和稀疏检索(BM25)结合起来。
向量搜索擅长语义匹配,BM25 擅长关键词匹配。两者互补,效果更好。
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
from langchain_community.vectorstores import Chroma
# 稀疏检索:BM25
bm25_retriever = BM25Retriever.from_texts(
documents_text_list,
k=5
)
# 稠密检索:向量
vector_retriever = Chroma.from_texts(
documents_text_list,
embedding=OpenAIEmbeddings()
).as_retriever(search_kwargs={"k": 5})
# 混合检索
ensemble = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6], # BM25 权重 0.4,向量权重 0.6
c=60
)
# 执行检索
query = "LangChain Agent 工具调用"
docs = ensemble.invoke(query)这里有个参数调优技巧:权重分配。
我们的经验是:
- 语义理解类查询(如”如何实现智能问答”):向量权重高(0.6-0.7)
- 关键词精准匹配类查询(如”Python 3.11 新特性”):BM25 权重高(0.5-0.6)
- 通用场景:平衡权重(0.5/0.5)
检索质量评估
怎么知道 EnsembleRetriever 真的有用?可以用 TruLens 来评估。
from trulens_eval import Feedback, TruChain
from trulens_eval.feedback.provider.openai import OpenAI
provider = OpenAI()
# 定义评估指标
relevance_feedback = Feedback(
provider.relevance,
name="Answer Relevance"
).on_input_output()
context_relevance_feedback = Feedback(
provider.context_relevance,
name="Context Relevance"
).on_input().on(context)
# 注册评估链
tru_recorder = TruChain(
chain=ensemble_retriever_chain,
feedbacks=[relevance_feedback, context_relevance_feedback],
feedback_mode="with_chain"
)
# 执行评估
with tru_recorder as recording:
response = ensemble_retriever_chain.invoke({"query": test_query})TruLens 会给出”答案相关性”和”上下文相关性”两个指标。我们实测下来,单向量检索的上下文相关性平均 0.72,Ensemble 后涨到 0.91。
5. 性能对比与最佳实践
说了这么多理论,实际效果怎么样?
我们在同一个测试集(500 个查询,覆盖 4 个业务场景)上跑了四种方案的对比:
| 路由策略 | 平均响应时间 | 检索准确率 | 适用场景 |
|---|---|---|---|
| 无路由(单库) | 1.2s | 72% | 单一业务场景 |
| 逻辑路由(LLM) | 1.8s | 85% | 多业务领域、复杂意图 |
| 语义路由 | 0.5s | 88% | 快速响应、查询类型固定 |
| Ensemble RRF | 1.0s | 92% | 混合场景、多源检索 |
解读几个关键数据
语义路由比逻辑路由快 3-4 倍。因为语义路由只调 Embedding API(约 100ms),逻辑路由要调 LLM(约 800ms)。如果你的查询类型比较固定,语义路由是首选。
Ensemble RRF 准确率最高。多检索器协同能覆盖不同语义空间,RRF 排序又能平衡各检索器的优势。代价是响应时间比单检索器稍长——多检索器并行查询需要更多资源。
无路由方案最慢。这反直觉,但想想就明白了:单库检索会返回大量无关文档,LLM 需要从更多噪声中提取答案,反而拖慢了生成速度。
最佳实践总结
根据我们的踩坑经验,给你几条建议:
1. 简单场景用语义路由
如果你的业务场景明确(比如只做 Python 文档问答),查询类型固定(问题解答、代码示例、故障排查三类),直接上 Semantic Router。响应快,费用低。
2. 复杂推理用逻辑路由
当查询涉及多跳推理或跨领域对比时,LLM 的语义理解能力更强。比如”Python 和 Go 的并发模型有什么区别”,LLM 能判断需要同时检索两个库。
3. 多源检索用 Ensemble
不确定用户意图时,可以同时检索多个库,用 RRF 合并。这比单路由更稳妥,但注意控制检索器数量——3-4 个是上限,再多会让响应时间爆炸。
4. 元数据丰富的库用 SelfQuery
如果你的文档有规范的元数据(分类、语言、时间、作者),SelfQueryRetriever 是神器。它能自动解析查询意图并生成精准过滤条件,减少检索噪声。
5. 动态调整策略
我们线上跑的是混合方案:先用语义路由做快速分流(100ms),如果匹配度低于阈值(比如 0.6),再回退到逻辑路由做精确判断。这样大部分简单查询都能快速响应,少数复杂查询也能得到正确处理。
总结
构建 RAG 系统时,很多人把精力花在 Embedding 模型调优、Prompt 工程上,却忽略了查询路由这个关键环节。
一个简单的决策:这个查询该走快速路径还是深度路径?用对方法,能让响应时间从 1.8 秒降到 0.5 秒,检索准确率从 72% 涨到 92%。
选择路由策略时,记住这几个原则:
- 简单查询走语义路由:速度快,费用低
- 复杂推理走逻辑路由:LLM 语义理解更准确
- 多源检索用 Ensemble:RRF 合并保证答案全面
- 元数据丰富用 SelfQuery:精准过滤减少噪声
我们团队目前在生产环境跑的是混合方案:语义路由做第一层分流,低置信度查询回退到逻辑路由,多源场景自动触发 Ensemble 检索。这套组合拳把客服机器人的问题解决率从 68% 提到了 89%。
完整的示例代码在 GitHub 仓库,你可以直接克隆下来跑跑看。有任何问题,欢迎在评论区交流。
实现 RAG 查询路由系统
构建支持语义路由、逻辑路由和多源检索的智能 RAG 路由架构
⏱️ 预计耗时: 45 分钟
- 1
步骤 1: 选择路由策略
根据业务场景选择路由方案:
• 查询类型固定 → 语义路由(响应快,约 100ms)
• 多业务领域 → 逻辑路由(准确率高,约 800ms)
• 混合场景 → Ensemble RRF(准确率最高 92%) - 2
步骤 2: 实现语义路由
使用 semantic-router 库快速搭建:
```python
from semantic_router import Route, RouteLayer
from semantic_router.encoders import OpenAIEncoder
python_route = Route(
name="python_docs",
utterances=["Python 异步编程", "Python 装饰器"]
)
route_layer = RouteLayer(
encoder=OpenAIEncoder(),
routes=[python_route]
)
``` - 3
步骤 3: 配置 EnsembleRetriever
合并多个检索器结果:
```python
from langchain.retrievers import EnsembleRetriever
ensemble = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6],
c=60
)
```
参数 c=60 是经验值,权重根据查询类型调整。 - 4
步骤 4: 评估检索质量
使用 TruLens 评估指标:
• 答案相关性(Answer Relevance)
• 上下文相关性(Context Relevance)
• 对比优化前后的指标变化
实测 Ensemble 后相关性从 0.72 提升到 0.91。
常见问题
语义路由和逻辑路由哪个更好?
EnsembleRetriever 的 RRF 参数 c 怎么设置?
如何处理路由失败的情况?
• 设置默认路由:语义路由匹配度低于阈值时,走默认检索器
• 回退逻辑路由:语义路由失败后,调用 LLM 做精确判断
• 多源检索:不确定时,用 Ensemble 同时检索多个库,用 RRF 合并
SelfQueryRetriever 对元数据有什么要求?
多检索器并行查询会不会太慢?
路由策略对 RAG 系统性能影响有多大?
14 分钟阅读 · 发布于: 2026年5月13日 · 修改于: 2026年7月14日


评论
使用 GitHub 账号登录后即可评论