
DeepAgents アーキテクチャ解説:Planning Tools、Sub-agents、ファイルシステムとシステムプロンプト
複雑なタスクで、AI エージェントはなぜいつも崩れてしまうのでしょうか。
技術テーマの調査を任せると、20ステップあたりから出力品質が落ち始めます。コードベースのリファクタを頼むと、半日かけても元の機能すら壊してしまいます。長文レポートを書かせると、途中から同じ内容の繰り返しが始まります。
私も以前、同じ轍を踏みました。従来型エージェントで LangGraph のベストプラクティスを調べてもらったときのことです。最初は筋が通っていましたが、30ステップを超えると「記憶喪失」状態に。調べた資料を忘れ、分析フレームも崩れ、最終レポートは矛盾だらけでした。
原因はいずれも同じです。従来型エージェントは「浅い(Shallow)」設計だからです。1ステップずつ反応するだけで、計画も記憶もサブタスク分割もありません。5000字のレポートをアウトラインなしで書かせるようなもので、途中で脱線するのは当然です。
一方、Claude Code、Deep Research、Manus などは数千行のリファクタや数十ページの調査レポートをこなします。何が違うのでしょうか。
答えは Deep Agent アーキテクチャです。LangChain 公式がこれを DeepAgents パッケージにまとめました。本記事では4本柱——Planning Tools、Sub-agents、File System、System Prompts——を分解して見ていきます。
なぜ Deep Agents が必要か
まず事実から。従来型エージェントは、10ステップを超えるタスクで成功率が半分以上落ちます。
Prompting Guide の研究でも、ステップ数が10を超えると Shallow Agent の出力品質が明らかに低下することが示されています。理由は単純で、「脳」がないからです。
従来設計は反応型です。指示を受ける → ツールを呼ぶ → 結果を返す。各ステップは独立し、長期計画も中間状態管理もありません。家全体の掃除を、順序も記録も指示せず任せるようなものです。キッチンを半分掃除してリビングへ行き、キッチンが未完了だと忘れてしまいます。
典型的な3つの崩壊パターンがあります。
深い調査タスク。例えば「LangGraph の本番ベストプラクティス」を調べさせると、検索・読取・抽出を繰り返します。20ステップ後には以前の資料がコンテキストウィンドウから押し出され、新しい検索結果が分析フレームを上書きします。結果は支離滅裂なレポートです。
コードリファクタタスク。数千行プロジェクトを任せると、モジュールAを直し、モジュールBも直しますが、依存関係を忘れます。最終的に、もともと動いていた機能まで壊れます。
長文コンテンツ生成。5000字の技術記事を書かせると、2000字あたりから同じ話の繰り返しや、テーマからの逸脱が始まります。
根っこはすべてコンテキストの暴走です。
Claude Code が大規模リファクタを、Deep Research が長大レポートを、Manus が多段タスクをこなせるのは、Deep Agent アーキテクチャという共通構造があるからです。
Deep Agent とは、エージェントに「脳」を持たせること——計画、タスク分割、記憶管理、進捗確認——を指します。LangChain がこれを DeepAgents としてパッケージ化したので、設計を具体的に見ていきましょう。
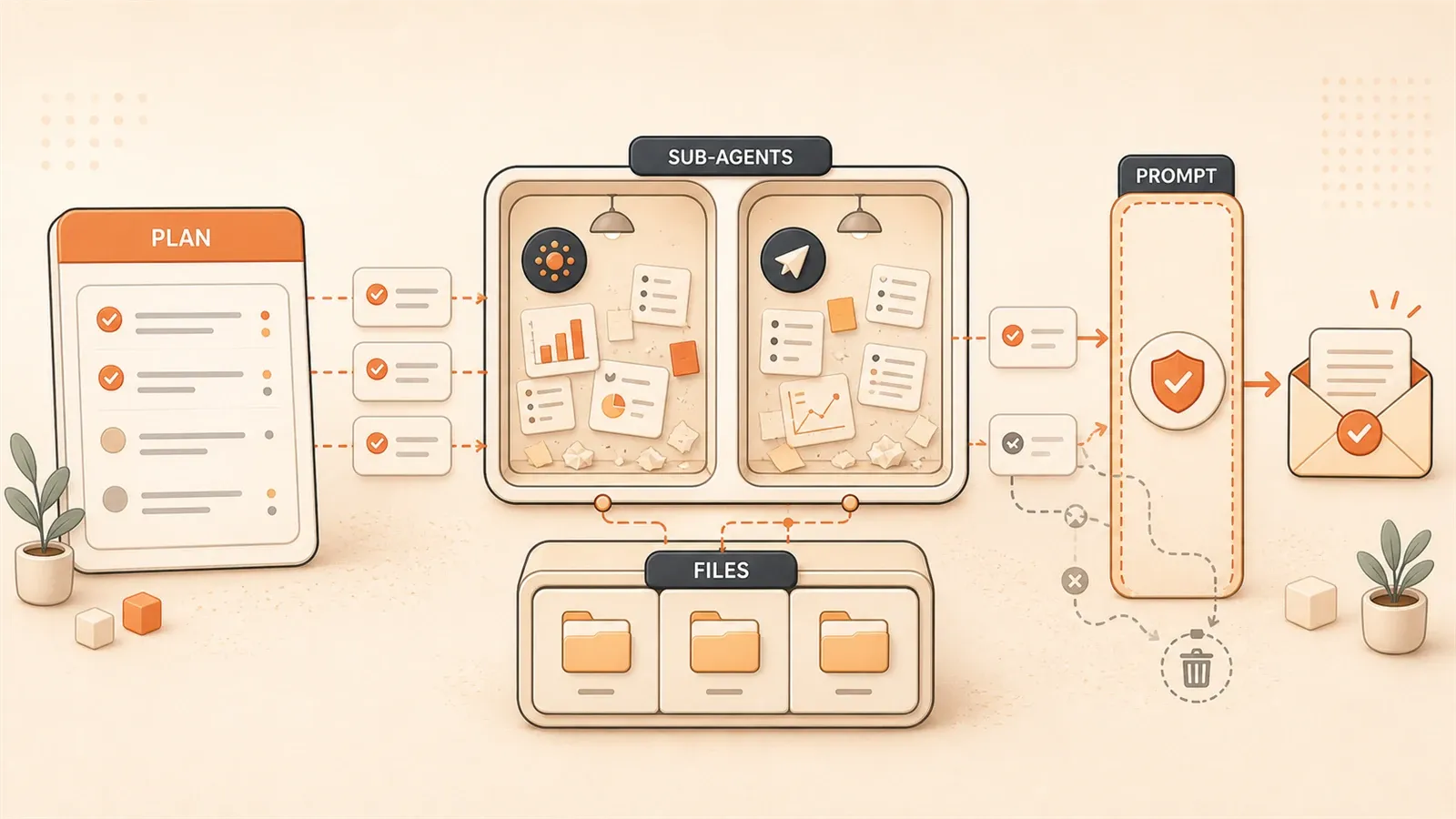
DeepAgents の4本柱アーキテクチャ
DeepAgents の設計思想は明快です。複雑タスクを管理可能な単位に分け、各単位に明確な責務を持たせます。
4本柱は連携します。Planning Tools が計画と進捗、Sub-agents が専門分担とコンテキスト分離、File System が記憶保存、System Prompts が行動境界を担います。オーケストラに例えるなら、指揮(Planning)、パート(Sub-agents)、楽譜置き場(File System)、演奏規則(System Prompts)です。
Planning Tools:エージェントに「脳」を与える
Planning Tools の核は todo_write です。
仕組みは興味深く、本質的には no-op(空操作)です。実タスクは実行せず、タスクリストの作成・更新だけを行います。しかしこのリストがコンテキストウィンドウ上のワーキングメモリとなり、実行全体を通じて計画と進捗を「見える化」します。
例:技術調査を任せると、まず todo_write で計画を作ります。
- [ ] LangGraph 公式ドキュメントを検索
- [ ] LangGraph State Machine 設計を読む
- [ ] ベストプラクティス事例を抽出
- [ ] コア設計パターンをまとめる
- [ ] 構造化レポートを出力各タスク完了ごとに [ ] を [x] に更新します。何ステップ進んでも、何が完了・未着手・進行中かを把握できます。
これが長期目標の一貫性問題を解きます。
従来型は20ステップ目で1ステップ目の目標を忘れがちです。Deep Agent の todo list は冷蔵庫の付箋のように、「いま何をすべきか」を常に思い出させます。
"Claude Code や Manus の planning tool も同原理——コンテキストウィンドウをワーキングメモリにして、エージェントが迷子にならないようにする"
Sub-agents:専門分担とコンテキスト分離
Sub-agents は2本目の柱です。
メインオーケストレーター(Orchestrator)が全体計画と割り当てを担い、専門サブエージェントが具体タスクを実行します。各サブエージェントは独立したコンテキストウィンドウを持ち、完了後は最終結果だけを返します。
4つの利点があります。
Context Preservation(コンテキスト保持)。オーケストレーターのコンテキストは、サブエージェントの中間ステップで汚れません。従来型は検索結果やページ全文をすべて詰め込みますが、Sub-agent は「重要情報をこれだけ見つけた」といった要約だけ返します。
Specialized Expertise(専門性)。research_subagent は検索・抽出、writer_subagent は構成・執筆、coder_subagent はコード分析に集中できます。
Reusability(再利用性)。同じサブエージェントを複数オーケストレーターから呼べます。research_subagent は調査・執筆・分析のどれにも使えます。
Fine-Grained Permissions(細粒度権限)。読み取り専用、書き込み専用、ネットワーク可など、サブエージェントごとに権限境界を分けられます。
"Orchestrator-Sub-agent アーキテクチャ(Task Decomposition Pattern)が推奨される——複雑タスクをサブタスクに分解し、専門ユニットへ委譲する"
実装はシンプルな API です。
from deepagents import create_deep_agent, create_subagent
# サブエージェントを定義
research_subagent = create_subagent(
name="research",
tools=[internet_search, read_url],
description="情報検索と抽出を担当"
)
writer_subagent = create_subagent(
name="writer",
tools=[write_file],
description="コンテンツ整理と出力を担当"
)
# メインエージェントを作成
agent = create_deep_agent(
subagents=[research_subagent, writer_subagent],
tools=[todo_write, read_file, write_file]
)オーケストレーターがサブエージェントを呼ぶと、DeepAgents がコンテキスト切り替えと結果受け渡しを自動処理します。
File System:コンテキストウィンドウの壁を超える
Deep Agent が記憶問題を解く中核です。
コンテキストウィンドウには上限があります。Claude は約200K、GPT-4 は約128K トークン。短タスクなら足りますが、数千行コードや数十ドキュメントではすぐ溢れます。
File System Backend の発想は、直接読み込みの代わりにファイル参照を使うことです。
中間結果をファイルシステムに置き、必要なとき read_file で都度読みます。参考文献を全部暗記せず、ノートに整理して必要時に開くのと同じです。
DeepAgents は3種類の Backend をサポートします。
StateBackend。メモリ保存。テストや短期タスク向き。セッション終了で消える。高速だが非永続。
FilesystemBackend。ローカルファイル保存。本番・永続化向き。再起動後も読める。永続だがローカル依存。
StoreBackend。クラウド保存。エンタープライズ・監査向き。バージョン管理と監査ログ可。信頼性高いが設定が重い。
FlowHunt の Context Management Strategy 比較表は3モードの違いを整理しています。
| モード | 利点 | 欠点 | 適用シナリオ |
|---|---|---|---|
| All-in-Context | シンプル | コンテキスト溢れやすい | 短タスク |
| File-Based References | コンテキスト節約 | ファイル管理ロジックが必要 | 長タスク・本番 |
| Hybrid | 柔軟性と効率のバランス | 設定が複雑 | エンタープライズ |
DeepAgents はデフォルト Hybrid——重要情報はコンテキスト、大量データはファイルシステム——です。
System Prompts:過小評価されがちな要
4本柱のうち最も軽視されやすいのが System Prompts です。
「役に立つアシスタントです」程度だと思われがちですが、Deep Agent では数百〜数千行のエンジニアリング文書になります。
Claude Code の System Prompt は数百行で、ツール呼び出し規約・ファイル操作・コードスタイルまで定義します。Deep Research は数千行で、調査方法論・抽出規約・出力テンプレートを含みます。
なぜこれほど詳細が必要か。長タスクでは境界ケースが次々出るからです。短い指示ではカバーしきれません。詳細 System Prompt の役割は次のとおりです。
行動境界の定義。いつ todo_write するか、いつ sub-agent に委譲するか、いつ直接返すか。
ツール呼び出しの規範。各ツールの使い方、引数形式、戻り値の扱い。read_file の引数がパスか ID か、返却が全文か要約か、など。
出力形式の設定。調査レポートは Markdown、リファクタは diff、生成コンテンツはテンプレート、など。
DeepAgents の Middleware Architecture が System Prompts を自動注入します。数千行を手書きする必要はありませんが、それがエージェント行動の「憲法」だと理解しておくことが重要です。
4本柱の説明は以上です。次は実践コードです。
DeepAgents 実践コード解説
技術調査エージェントの完全例を見ます。
from deepagents import create_deep_agent, create_subagent
from langchain_community.tools import TavilyInternetSearch
# 1. ツール定義
search_tool = TavilyInternetSearch(
name="internet_search",
description="インターネット検索で情報取得"
)
# 2. サブエージェント定義
research_subagent = create_subagent(
name="research",
tools=[search_tool],
system_prompt="あなたは情報検索の専門家です。\
重要情報の検索と抽出が任務です。\
構造化された調査結果のみ返し、中間ステップは含めないでください。",
description="情報検索担当サブエージェント"
)
writer_subagent = create_subagent(
name="writer",
tools=[], # writer は外部ツール不要
system_prompt="あなたはコンテンツ整理の専門家です。\
調査結果を整理し構造化レポートを出力します。\
Markdown で明確な章構成にしてください。",
description="コンテンツ出力担当サブエージェント"
)
# 3. Deep Agent 作成
agent = create_deep_agent(
subagents=[research_subagent, writer_subagent],
tools=[todo_write, read_file, write_file],
backend="filesystem" # ファイルシステム保存
)
# 4. タスク実行
result = agent.invoke(
"LangGraph のベストプラクティスを調査し、\
構造化レポートを出力してください"
)実行フローは次のとおりです。
Step 1:Plan。todo_write で計画リストを作成。
todo_write([
"LangGraph 公式ドキュメントを検索",
"コアアーキテクチャ設計を読む",
"ベストプラクティス事例を抽出",
"設計パターンをまとめる",
"構造化レポートを出力"
])Step 2:Delegate。research_subagent に検索を委譲。
call_subagent("research", "LangGraph ベストプラクティス関連ドキュメントを検索")research_subagent が internet_search を呼び、結果から要点を抽出し、要約だけをオーケストレーターへ返します。オーケストレーターのコンテキストには「5つの重要ベストプラクティスを発見」のような摘要だけが入ります。
Step 3:Update。todo list を更新。
todo_write([
"[x] LangGraph 公式ドキュメントを検索",
"[x] コアアーキテクチャ設計を読む",
"[ ] ベストプラクティス事例を抽出",
...
])Step 4:継続。writer_subagent で構成し、write_file で最終レポート出力。
call_subagent("writer", "調査結果を整理してレポート出力")
write_file("langgraph_best_practices.md", report_content)実行ログのイメージ:
[Step 1] todo_write: 5タスク項目を作成
[Step 2] call_subagent(research): 情報検索開始
[Step 3] internet_search: "LangGraph best practices" を検索
[Step 4] read_url: 公式ドキュメント3件を読む
[Step 5] subagent_complete: research が構造化結果を返却
[Step 6] todo_write: 進捗更新、2項目完了
[Step 7] call_subagent(writer): コンテンツ整理開始
[Step 8] subagent_complete: writer が Markdown レポート返却
[Step 9] write_file: レポートをファイル出力
[Step 10] todo_write: 全タスク完了オーケストレーターのコンテキストは常にクリーン——タスクリストとサブエージェント要約だけで、中間ノイズはありません。
これが Deep Agent の強みです。構造化フロー、コンテキスト管理、専門分担。
他フレームワークとの比較
DeepAgents だけが選択肢ではありません。LangGraph、AutoGen、CrewAI、SmolAgents など、用途ごとに強みが異なります。
| フレームワーク | コア特性 | 向くシーン | 学習曲線 |
|---|---|---|---|
| DeepAgents | Planning + Memory + Sub-agents を一式提供 | 複雑推論ワークフロー・素早い立ち上げ | 低 |
| LangGraph | ステートフルワークフロー・低レイヤー編成 | 本番エージェント・細かい制御 | 中 |
| AutoGen | マルチエージェントグラフ・.NET 対応 | エンタープライズ Pipeline・Microsoft 系 | 中高 |
| CrewAI | 高性能エージェントチーム・ロールプレイ | 本番自動化・チーム協調シミュレーション | 中 |
| SmolAgents | 軽量・コードファースト | 迅速プロトタイプ・単純タスク | 低 |
主な違い:
DeepAgents vs LangGraph。DeepAgents は LangGraph 上の Deep Agent 特化ラッパー。Planning、File System、Sub-agent 管理が済んでいます。LangGraph はノードとエッジを自由設計できる低レイヤーですが、Memory と Planning は自前です。素早く Deep Agent なら DeepAgents、底層カスタムなら LangGraph。
DeepAgents vs AutoGen。AutoGen は Microsoft 製で、エージェント同士の対話・議論・交渉が強み。DeepAgents はタスク分解と実行、AutoGen は協調とコミュニケーション寄り。
DeepAgents vs CrewAI。CrewAI はロールプレイ(研究員・編集・開発者など)を強調。Sub-agent 構造は似ますが、CrewAI はキャラ設定と対話、DeepAgents はタスク分解と分離が中心。
DeepAgents vs SmolAgents。SmolAgents は Hugging Face の軽量フレームワーク。ツール呼び出しより Python コード直接実行。プロトタイプ向きで、長期複雑タスクには向きません。
"選定はシーン次第。DeepAgents は複雑推論、LangGraph は本番システム、AutoGen/CrewAI はマルチエージェント協調、SmolAgents はアイデア検証。万能フレームワークはなく、適合するものだけがある"
本番デプロイとベストプラクティス
本番で DeepAgents を使う際の要点です。
Backend 選定
StateBackend:テスト・短期タスク。メモリのみで IO 遅延なし。再起動で状態消失。ユニットテストや検証向き。
FilesystemBackend:本番・永続化。ファイル書き込みで再起動後も復元。IO コストあり。長タスクや本番デプロイ向き。
StoreBackend:エンタープライズ・監査。クラウド DB に保存、バージョン管理と監査ログ。DB 接続・権限設定が必要。コンプライアンス要件向き。
設定例:
from deepagents import create_deep_agent, FilesystemBackend
agent = create_deep_agent(
subagents=[research_subagent, writer_subagent],
backend=FilesystemBackend(
base_path="/var/agent-state", # 保存パス
max_file_size=10 * 1024 * 1024, # 単一ファイル最大10MB
cleanup_after_days=30 # 30日後に古いファイルを削除
)
)サブエージェント粒度
過度な分割は避けてください。
調査を search_google、search_bing、read_wikipedia… と10個に割った例では、呼び出しオーバーヘッドの方が実行時間を上回りました。
目安は3〜5個:
- research:情報検索・抽出
- analysis:データ処理・推論
- writer:構成・出力
- reviewer:品質チェック(任意)
research が執筆を、writer が検索を——責務を混ぜないことが重要です。
パフォーマンス最適化
ファイルは必要時読み込み。中間結果を一括 read_file しない。パスだけコンテキストに持ち、内容は必要時ロード。
Context Summarization の適切利用。長タスクでは実行ログが膨らみます。DeepAgents は閾値超過で自動要約し、冗長ログを短い状態記述に圧縮。ただし重要情報は失わないよう注意。
agent = create_deep_agent(
...,
context_management={
"summarization_threshold": 50000, # 50K トークンで要約
"preserve_last_n_steps": 5 # 直近5ステップは詳細保持
}
)エラー処理と検証
長い実行ほど失敗確率も上がります。
LLM-as-a-Judge。別 LLM で出力品質を検査。reviewer_subagent が writer のレポートの論理穴や欠落をチェック。
人間チェックポイント。重要判断前にユーザー確認。調査完了後、方向性を確認してから続行。
agent = create_deep_agent(
...,
verification={
"auto_verify": True, # 自動検証を有効
"human_checkpoint": "before_output" # 出力前に人間確認
}
)まとめ
DeepAgents の4本柱を振り返ります。
Planning Tools — todo_write をワーキングメモリにし、長期目標の一貫性を保つ。
Sub-agents — 専門分担とコンテキスト分離。オーケストレーターはクリーンなまま。
File System — ファイル参照と必要時読み込みで、コンテキストウィンドウ制限を回避。
System Prompts — 数百〜数千行の規約で、境界ケースまで行動を定義。
4本柱が協調し、エージェントを「反応実行」から「構造化推論」へ進化させます。Claude Code、Deep Research、Manus の成功がその有効性を示しています。
次のアクション:
- DeepAgents で最初の長タスクエージェントを試す。サンプルは公式 GitHub:langchain-ai/deepagents。
- LangChain 公式ドキュメントを深掘り。DeepAgents は docs.langchain.com/oss/python/deepagents。
- AI 開発実践シリーズも要チェック。LangGraph ステートマシン設計や Agent Memory 最適化など、今後もアーキテクチャ分析を続けます。
FAQ
DeepAgents と LangGraph の違いは?
いつ Sub-agents を使い、単一エージェントにしないべき?
• タスクが10ステップ超でコンテキストが溢れやすい
• 調査・執筆・コード分析など専門分担が必要
• 中間ステップでコンテキストが汚れるが、最終的には要約だけ欲しい
• 読み取り専用・書き込み専用・ネットワークアクセスなど細かい権限制御が必要
File System Backend の3モードはどう選ぶ?
• StateBackend:テスト環境・短期タスク。高速だが永続化なし
• FilesystemBackend:本番・永続化が必要。信頼性高いが IO コストあり
• StoreBackend:エンタープライズ・監査追跡が必要。バージョン管理可だが設定が複雑
サブエージェントはどの粒度で分割すべき?
DeepAgents はどんなタスク向き?
8分で読めます · 公開日: 2026年4月26日 · 更新日: 2026年7月27日
AI Agent エンジニアリング: アーキテクチャ、tool calling、評価、復旧
検索からこのページに来た場合は、前後の記事もあわせて読むと同じテーマの理解がかなり早く深まります。


コメント
GitHubアカウントでログインしてコメントできます