
DeepAgents 架构解析:规划工具、子代理与文件系统
你的 AI Agent 为什么总是在复杂任务中崩溃?
让它研究一个技术主题,跑了 20 步后输出质量就开始下滑。让它重构一个代码库,改了半天连原本的功能都搞丢了。让它写一篇长篇报告,写到一半就开始重复废话。
我之前踩过这个坑。那时候用传统 Agent 做深度研究,想让它帮我调研 LangGraph 的最佳实践。刚开始输出挺有条理,但跑了三十多步之后,它就开始”失忆”——前面查过的资料忘了,原本的分析框架也乱了,最后给我的报告东拼西凑,前后矛盾。
这些问题的根源都是同一个:传统 Agent 是”Shallow”的。它们只会单步反应式执行,没有规划能力,没有记忆系统,没有子任务拆分。就像你让一个人写 5000 字的报告却不给大纲,写到一半肯定跑偏。
但 Claude Code、Deep Research、Manus 这些 Agent 却能完成复杂任务——几千行代码的项目重构、几十页的深度研究报告。它们用了什么方法?
答案就是 Deep Agent 架构。LangChain 官方把这个架构封装成了 DeepAgents 包,今天来拆解它的四大支柱:规划工具、子代理、文件系统和系统提示。
为什么需要 Deep Agents?
先说一个事实:传统 Agent 在超过 10 步的任务中成功率会掉一半以上。
这不是瞎说。Prompting Guide 的研究数据显示,当任务步骤超过 10 个,Shallow Agent 的输出质量就开始明显下滑。为什么?因为它没有”脑子”。
传统的 Agent 设计是反应式的:收到指令 → 调用工具 → 返回结果。每一步都是独立的,没有长期规划,没有中间状态管理。打个比方,就像你让一个人打扫整个房子,却不告诉他打扫顺序,也不让他记录哪些房间已经打扫过了。他可能先把厨房扫了一半,突然跑去客厅,然后又忘记厨房还没做完。
三个最典型的崩溃场景:
深度研究任务。你让 Agent 调研某个技术主题,比如”LangGraph 在生产环境中的最佳实践”。它开始搜索、读取文档、提取信息。20 步之后,原本查过的资料已经被挤出 Context Window,新的搜索结果覆盖了之前的分析框架。最后输出一份前言不搭后语的报告。
代码重构任务。你让 Agent 重构一个有几千行代码的项目。它改了一个模块,又改另一个模块,但两个模块之间有依赖关系——它忘了。改到最后,原本能跑的功能全挂了。
长篇内容生成。你让 Agent 写一篇 5000 字的技术文章。写到第 2000 字的时候,它开始重复前面说过的话,或者偏离原本的选题方向。
这些问题的核心都是 Context 失控。
Claude Code 能处理几千行代码的项目重构,Deep Research 能产出几十页的结构化报告,Manus 能完成复杂的多步骤任务。它们不是魔法,而是用了一套统一的结构:Deep Agent 架构。
Deep Agent 就是让 Agent 有”脑子”——会规划、会拆分任务、会管理记忆、会检查进度。LangChain 把这套架构封装成 DeepAgents,来看看它的具体设计。
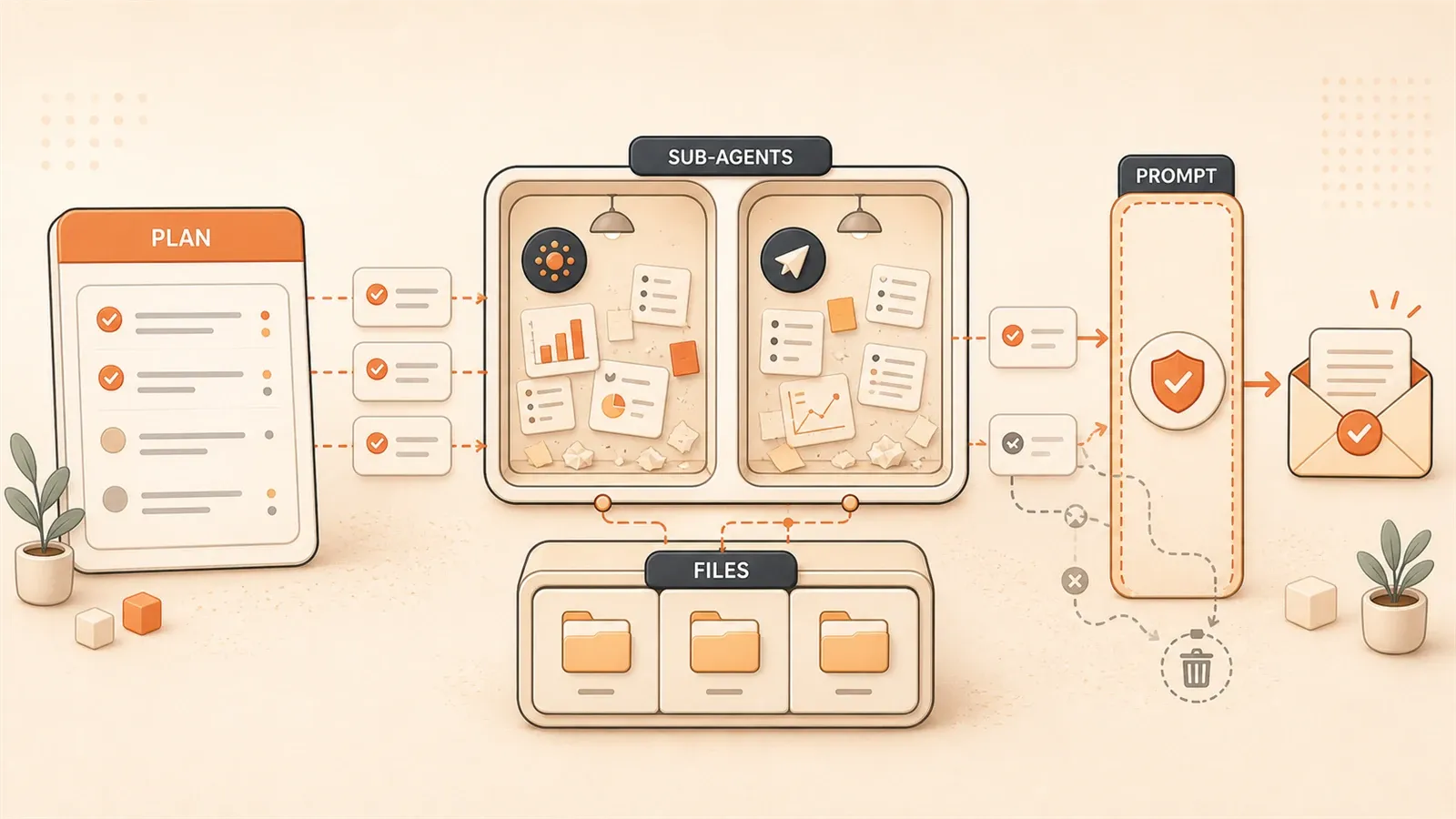
DeepAgents 四大支柱架构
DeepAgents 的设计哲学很清晰:把复杂任务拆成可管理的单元,每个单元有明确职责。
四个支柱相互配合:Planning Tools 管规划和进度追踪,Sub-agents 实现专业分工和 Context 隔离,File System 解决记忆存储问题,System Prompts 定义行为边界。它们像交响乐团——有指挥(Planning)、有不同乐器组(Sub-agents)、有乐谱存储(File System)、有演奏规则(System Prompts)。
Planning Tools:让 Agent 有个”脑子”
Planning Tools 的核心是 todo_write。
它的工作原理很有意思——本质上是个 no-op(空操作)。它不执行任何实际任务,只是创建和更新任务列表。但这些任务列表通过 Context Window 作为 working memory,让 Agent 在整个执行过程中都能”看到”自己的计划和进度。
举个例子:你让 Agent 做一个技术调研。它会先用 todo_write 创建一个计划:
- [ ] 搜索 LangGraph 官方文档
- [ ] 阅读 LangGraph State Machine 设计
- [ ] 提取最佳实践案例
- [ ] 总结核心设计模式
- [ ] 输出结构化报告每完成一个任务,Agent 就更新这个列表,把 [ ] 改成 [x]。这样一来,不管执行了多少步,Agent 都能随时看到自己的进度——哪些做完,哪些还没开始,哪些正在进行。
这解决了一个核心问题:长期目标一致性。
传统 Agent 执行到第 20 步的时候,可能已经忘了第 1 步定下的目标是什么。但 Deep Agent 的 todo list 像是贴在冰箱上的备忘条,随时提醒它”你到底要干什么”。
"Claude Code 和 Manus 的 planning tool 都是这个原理——用 Context Window 作为 working memory,保持 Agent 不迷失方向"
Sub-agents:专业分工,Context 隔离
Sub-agents 是 Deep Agent 的第二个支柱。
它的设计逻辑是这样的:一个主编排器(Orchestrator)负责整体规划和任务分配,多个专业化子代理负责执行具体任务。每个子代理有独立的 Context Window,执行完之后只返回最终结果给编排器。
这带来四个关键优势:
Context Preservation。编排器的 Context Window 不会被子代理的中间步骤污染。传统 Agent 执行搜索任务时,会把所有搜索结果、网页内容、提取过程都塞进 Context。但 Sub-agent 执行完之后,只返回一个干净的结果——“我找到了这些关键信息”。编排器的 Context 保持清爽。
Specialized Expertise。每个子代理可以专注一个领域。research_subagent 专门做信息检索和提取,writer_subagent 专门做内容组织,coder_subagent 专门做代码分析。专业化分工让每个子代理在自己的领域做得更好。
Reusability。同一个子代理可以被多个编排器调用。比如 research_subagent 可以用在调研任务、写作任务、分析任务中。写一次,到处用。
Fine-Grained Permissions。子代理可以有不同的权限边界。有的子代理只能读文件,有的可以写文件,有的可以访问网络。精细化权限控制降低安全风险。
"推荐 Orchestrator-Sub-agent 架构,也称为 Task Decomposition Pattern——把复杂任务分解成子任务,每个子任务交给专门的处理单元"
具体怎么实现?DeepAgents 提供了简单的 API:
from deepagents import create_deep_agent, create_subagent
# 定义子代理
research_subagent = create_subagent(
name="research",
tools=[internet_search, read_url],
description="专门负责信息检索和提取"
)
writer_subagent = create_subagent(
name="writer",
tools=[write_file],
description="专门负责内容组织和输出"
)
# 创建主 Agent
agent = create_deep_agent(
subagents=[research_subagent, writer_subagent],
tools=[todo_write, read_file, write_file]
)编排器调用子代理时,DeepAgents 会自动处理 Context 切换和结果传递。
File System:突破 Context Window 限制
这是 Deep Agent 解决记忆问题的核心方案。
Context Window 有大小限制。Claude 大概 200K tokens,GPT-4 约 128K tokens。对于短任务,这足够用。但对于长任务——比如处理几千行代码、阅读几十篇文档——这些空间很快就被撑爆了。
File System Backend 的解决思路很聪明:用文件引用代替直接加载。
Agent 不把所有内容都塞进 Context Window,而是把中间结果存储到文件系统。需要用到某个文件时,再通过 read_file 工具按需读取。就像你做研究时不会把所有参考文献都背在脑子里,而是把它们整理成文档,需要时打开查看。
DeepAgents 支持三种 Backend:
StateBackend。内存存储,适合测试环境和短期任务。Agent 的状态和中间结果存储在内存中,会话结束后就没了。快速但不持久。
FilesystemBackend。本地文件系统存储,适合生产环境和需要持久化的场景。Agent 的中间结果写入本地文件,下次运行时还能读取。持久但依赖本地存储。
StoreBackend。云端存储,适合企业级部署和需要审计追踪的场景。Agent 的状态存储在云端数据库,支持版本控制和审计日志。可靠但配置复杂。
选择哪种 Backend 取决于你的场景。如果是快速测试,用 StateBackend;如果是生产部署,用 FilesystemBackend;如果是企业级应用需要审计,用 StoreBackend。
FlowHunt 的 Context Management Strategy 对比表格把这三种模式讲得很清楚:
| 模式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| All-in-Context | 简单直接 | Context 容易溢出 | 短任务 |
| File-Based References | 节省 Context 空间 | 需要文件管理逻辑 | 长任务、生产环境 |
| Hybrid | 平衡灵活性和效率 | 配置复杂 | 企业级应用 |
DeepAgents 默认用 Hybrid 模式——关键信息保持在 Context,大量数据存储在文件系统。
System Prompts:被低估的关键
System Prompts 是四大支柱里最容易被忽视的一个。
很多人以为 System Prompt 就是几句简单指令,比如”你是一个有用的助手”。但 Deep Agent 的 System Prompts 实际上是数百到数千行的工程化文档。
Claude Code 的 System Prompt 有几百行,定义了完整的工具调用规范、文件操作流程、代码风格约束。Deep Research 的 System Prompt 有上千行,包含研究方法论、信息提取规范、输出格式模板。
为什么需要这么详细的 System Prompt?
因为 Agent 在长任务中会遇到各种边界情况。简短的指令无法覆盖所有场景。详细 System Prompt 的作用是:
定义行为边界。什么情况下应该调用 todo_write,什么情况下应该交给 sub-agent,什么情况下应该直接返回结果。这些规则要写得足够详细,Agent 才能做出正确判断。
规范工具调用。每个工具怎么用,参数格式是什么,返回结果怎么处理。比如 read_file 工具的参数是文件路径还是文件 ID,返回的是原始内容还是摘要。
设定输出格式。不同任务类型有不同的输出格式要求。研究报告用 Markdown 结构,代码重构用 diff 格式,内容生成用特定模板。
DeepAgents 的 Middleware Architecture 会自动注入 System Prompts。你不需要手动写几千行,框架会根据你的配置自动生成。但理解 System Prompts 的作用很重要——它是 Agent 行为的”宪法”。
四个支柱都讲完了。下面看实战代码。
DeepAgents 实战代码解析
来看一个完整的代码示例,实现一个技术调研 Agent。
from deepagents import create_deep_agent, create_subagent
from langchain_community.tools import TavilyInternetSearch
# 1. 定义工具
search_tool = TavilyInternetSearch(
name="internet_search",
description="搜索互联网获取信息"
)
# 2. 定义子代理
research_subagent = create_subagent(
name="research",
tools=[search_tool],
system_prompt="你是信息检索专家。\
你的任务是搜索和提取关键信息。\
只返回结构化的研究结果,不要包含中间步骤。",
description="负责信息检索的子代理"
)
writer_subagent = create_subagent(
name="writer",
tools=[], # writer 不需要外部工具
system_prompt="你是内容组织专家。\
你的任务是整理研究结果,输出结构化报告。\
使用 Markdown 格式,包含清晰的章节结构。",
description="负责内容输出的子代理"
)
# 3. 创建 Deep Agent
agent = create_deep_agent(
subagents=[research_subagent, writer_subagent],
tools=[todo_write, read_file, write_file],
backend="filesystem" # 使用文件系统存储
)
# 4. 执行任务
result = agent.invoke(
"调研 LangGraph 的最佳实践,\
输出一份结构化的研究报告"
)执行流程是这样的:
第一步:Plan。Agent 调用 todo_write 创建计划列表。
todo_write([
"搜索 LangGraph 官方文档",
"阅读核心架构设计",
"提取最佳实践案例",
"总结设计模式",
"输出结构化报告"
])第二步:Delegate。Agent 调用 research_subagent 执行检索任务。
call_subagent("research", "搜索 LangGraph 最佳实践相关文档")research_subagent 会调用 internet_search 工具,获取搜索结果,提取关键信息,然后返回一个干净的结构化结果给编排器。编排器的 Context Window 只收到”这里找到 5 个关键最佳实践”这样的摘要,而不是所有搜索结果的原始内容。
第三步:Update。Agent 更新 todo list,标记完成状态。
todo_write([
"[x] 搜索 LangGraph 官方文档",
"[x] 阅读核心架构设计",
"[ ] 提取最佳实践案例",
...
])第四步:继续执行。Agent 调用 writer_subagent 组织内容,然后 write_file 输出最终报告。
call_subagent("writer", "整理研究结果,输出报告")
write_file("langgraph_best_practices.md", report_content)执行日志看起来是这样的:
[Step 1] todo_write: 创建 5 个任务项
[Step 2] call_subagent(research): 开始信息检索
[Step 3] internet_search: 搜索 "LangGraph best practices"
[Step 4] read_url: 读取 3 篇官方文档
[Step 5] subagent_complete: research 返回结构化结果
[Step 6] todo_write: 更新进度,完成 2 项
[Step 7] call_subagent(writer): 开始内容组织
[Step 8] subagent_complete: writer 返回 Markdown 报告
[Step 9] write_file: 输出报告到文件
[Step 10] todo_write: 全部任务完成整个流程中,编排器的 Context Window 始终保持干净——只有任务列表、子代理返回的摘要结果,没有中间步骤的噪音。
这就是 Deep Agent 的威力:结构化流程、Context 管理、专业分工。
与其他 Agent 框架对比
DeepAgents 不是唯一的选择。市面上还有 LangGraph、AutoGen、CrewAI、SmolAgents 等框架。它们各有侧重,适用场景不同。
一张对比表说清楚:
| 框架 | 核心特性 | 适用场景 | 学习曲线 |
|---|---|---|---|
| DeepAgents | Planning + Memory + Sub-agents,封装完整 | 复杂推理工作流,快速上手 | 低 |
| LangGraph | 状态化工作流,底层编排能力强 | 生产级 Agent 系统,需要精细控制 | 中 |
| AutoGen | 多代理图,支持 .NET | 企业级 Pipeline,微软生态 | 中高 |
| CrewAI | 高性能代理团队,角色扮演 | 生产级自动化,团队协作模拟 | 中 |
| SmolAgents | 轻量级,代码优先 | 快速原型开发,简单任务 | 低 |
几个关键区别:
DeepAgents vs LangGraph。DeepAgents 是 LangGraph 的上层封装,专注于 Deep Agent 模式。它把 Planning Tools、File System Backend、Sub-agent Management 这些通用能力封装好了,你不需要自己搭建。LangGraph 更底层,提供状态机和工作流编排能力,你可以自由定义每个节点和边,但需要自己实现 Memory 和 Planning。
简单说:想快速搭建 Deep Agent,用 DeepAgents;想做底层定制,用 LangGraph。
DeepAgents vs AutoGen。AutoGen 是微软的框架,支持多代理对话和 Pipeline 编排。它的特点是代理之间可以互相对话,形成辩论、协商等复杂交互模式。DeepAgents 更偏向任务分解和执行,AutoGen 更偏向代理协作和沟通。
简单说:想做代理团队协作、辩论协商,用 AutoGen;想做任务分解、专业分工,用 DeepAgents。
DeepAgents vs CrewAI。CrewAI 强调”角色扮演”——每个代理有不同的角色定位(研究员、编辑、程序员),它们协作完成任务。和 DeepAgents 的 Sub-agent 模式类似,但 CrewAI 更强调角色的人设和交互,DeepAgents 更强调任务的分解和隔离。
简单说:想模拟团队协作、角色扮演,用 CrewAI;想做技术性任务分解,用 DeepAgents。
DeepAgents vs SmolAgents。SmolAgents 是 Hugging Face 出的轻量框架,特点是代码优先——Agent 直接写 Python 代码来执行任务,而不是调用工具。它适合快速原型开发,但不适合复杂的长任务。
简单说:想快速试一个简单 Agent,用 SmolAgents;想做复杂长任务,用 DeepAgents。
"框架选择要看你的场景。DeepAgents 适合处理复杂推理任务,LangGraph 适合生产级系统,AutoGen 和 CrewAI 适合多代理协作,SmolAgents 适合快速验证想法。没有万能的框架,只有适合的框架"
生产部署与最佳实践
把 DeepAgents 用在生产环境,有几个关键点要注意。
Backend 选择策略
三种 Backend 的选择逻辑:
StateBackend:测试环境、短期任务。优点是快——所有数据在内存,读写没有 IO 延迟。缺点是不持久——Agent 重启后状态全丢。适合单元测试、快速验证、短期任务。
FilesystemBackend:生产环境、持久化需求。优点是可靠——数据写入文件系统,重启后还能读取。缺点是有 IO 成本——读写文件比内存慢。适合生产部署、长任务、需要持久化。
StoreBackend:企业级、需要审计追踪。优点是可控——数据存储在云端数据库,支持版本管理和审计日志。缺点是复杂——需要配置数据库连接、权限管理。适合企业应用、合规要求、审计需求。
一个配置示例:
from deepagents import create_deep_agent, FilesystemBackend
agent = create_deep_agent(
subagents=[research_subagent, writer_subagent],
backend=FilesystemBackend(
base_path="/var/agent-state", # 存储路径
max_file_size=10 * 1024 * 1024, # 单文件最大 10MB
cleanup_after_days=30 # 30 天后清理旧文件
)
)子代理粒度设计
不要过度拆分。
有人把一个调研任务拆成 10 个子代理:search_google、search_bing、read_wikipedia、read_github、extract_summary、extract_quotes、format_markdown、check_citations… 结果编排器调用子代理的时间比实际执行任务的时间还长。
合理的设计是 3-5 个核心子代理:
- research:负责所有信息检索和提取
- analysis:负责数据处理和逻辑推理
- writer:负责内容组织和输出
- reviewer:负责质量检查和校验(可选)
每个子代理有明确的职责边界。research 子代理不应该去做内容组织,writer 子代理不应该去做信息检索。职责分明,调用清晰。
性能优化
两个关键点:
文件按需读取。不要一次性 read_file 所有中间结果。Agent 在执行过程中,根据当前任务的需要读取相关文件。DeepAgents 的文件引用机制就是为此设计的——文件路径保存在 Context,内容在需要时才加载。
合理使用 Context Summarization。长任务执行过程中,Context Window 可能会积累很多内容。DeepAgents 支持中间步骤的自动摘要——把冗长的执行记录压缩成简短的状态描述。这能节省 Context 空间,但要注意摘要的准确性——关键信息不能丢。
agent = create_deep_agent(
...,
context_management={
"summarization_threshold": 50000, # 50K tokens 时触发摘要
"preserve_last_n_steps": 5 # 保留最近 5 步的详细记录
}
)错误处理和验证
Deep Agents 的执行过程长,出错概率也大。要有错误处理机制:
LLM-as-a-Judge。用另一个 LLM 检查 Agent 的输出质量。比如 reviewer_subagent 检查 writer_subagent 输出的报告是否有逻辑漏洞、信息遗漏。
人工介入点。在关键决策点设置人工确认。比如 Agent 完成调研后,暂停等待用户确认方向是否正确,再继续执行。
agent = create_deep_agent(
...,
verification={
"auto_verify": True, # 启用自动验证
"human_checkpoint": "before_output" # 输出前人工确认
}
)总结
回顾一下 DeepAgents 的四大支柱:
Planning Tools 让 Agent 有规划能力,todo_write 通过 Context Window 作为 working memory,保持长期目标一致性。
Sub-agents 实现专业分工和 Context 隔离,编排器的 Context 保持干净,子代理执行中间步骤不污染主流程。
File System 解决 Context Window 限制,用文件引用代替直接加载,按需读取节省空间。
System Prompts 定义 Agent 的行为边界,数百到数千行的工程化文档覆盖各种边界情况。
这四个支柱协同工作,让 Agent 从”反应式执行”进化到”结构化推理”。Claude Code、Deep Research、Manus 的成功证明了这个架构的有效性。
下一步行动建议:
- 尝试用 DeepAgents 构建你的第一个长任务 Agent。官方 GitHub 仓库有完整的示例代码:langchain-ai/deepagents。
- 阅读 LangChain 官方文档深入学习。DeepAgents 的文档在 docs.langchain.com/oss/python/deepagents。
- 关注 AI 开发实战系列。后续会有更多 Agent 架构的深度分析,包括 LangGraph 状态机设计、Agent Memory 系统优化等主题。
常见问题
DeepAgents 和 LangGraph 有什么区别?
什么时候应该用 Sub-agents 而不是单个 Agent?
• 任务步骤超过 10 个,Context 容易溢出
• 需要专业化分工(如研究、写作、代码分析)
• 中间步骤会污染 Context,但最终只需要摘要结果
• 需要精细化权限控制(如只读、只写、网络访问)
File System Backend 的三种模式怎么选?
• StateBackend:测试环境、短期任务,快速但不持久
• FilesystemBackend:生产环境、需要持久化,可靠但有 IO 成本
• StoreBackend:企业级、需要审计追踪,支持版本控制但配置复杂
子代理应该拆分到什么粒度?
DeepAgents 适合什么样的任务?
18 分钟阅读 · 发布于: 2026年4月26日 · 修改于: 2026年7月27日


评论
使用 GitHub 账号登录后即可评论