Schritt für Schritt: Low-Latency Audio-Video-KI-Assistent mit Gemini Multimodal Live API
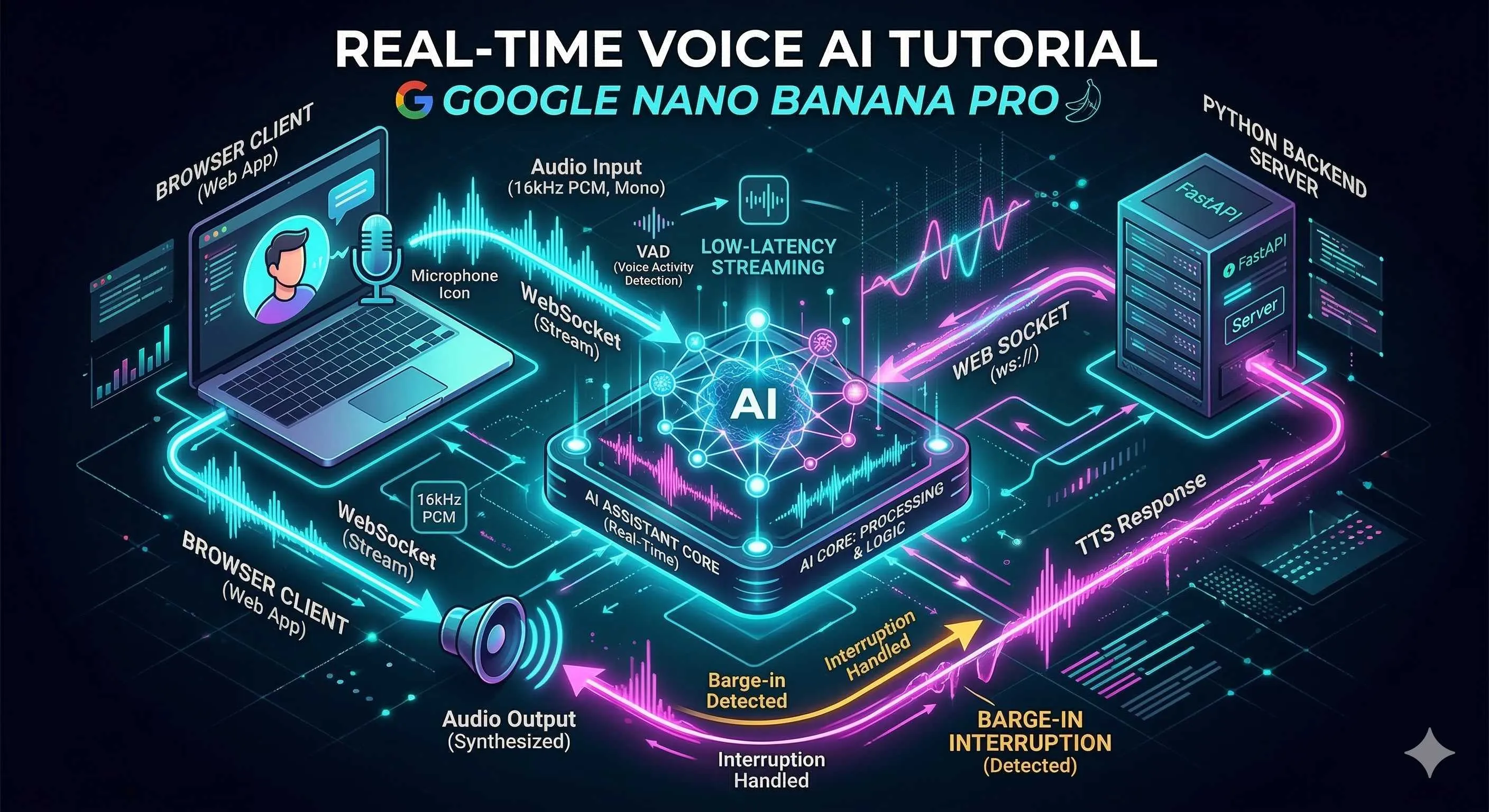
Die Gemini Live API unterstützt Audio-Ein- und -Ausgabe nativ; die End-to-End-Architektur hält die Latenz unter 500 ms – ohne ASR/TTS-Umweg. In diesem Artikel zeigen wir, wie Sie mit dieser API einen wirklich Echtzeit-fähigen KI-Assistenten aufbauen.
Was ist die Gemini Multimodal Live API?
Zuerst die Grundlagen. Wie funktioniert die klassische Gemini API? Sie senden Text, Sie erhalten Text – simpel. Für Sprachinteraktion brauchen Sie ASR (Speech-to-Text) und TTS (Text-to-Speech) dazwischen; jeder Umweg erhöht die Latenz.
Die Gemini Multimodal Live API ist anders: Sie unterstützt Audio-Ein- und -Ausgabe nativ. Mikrofon-Audio geht direkt rein, die Antwort kommt als Audiostream zurück – ohne Formatkonvertierung dazwischen. Diese End-to-End-Architektur drückt die Latenz unter 500 ms.
In einem Smart-Home-Projekt habe ich das getestet. Der Nutzer sagte „Dimme das Wohnzimmerlicht etwas“, und die KI antwortete fast unmittelbar nach dem Satz – so flüssig, dass man leicht vergisst, dass es ein Programm ist.
Aktuell unterstütztes Modell: gemini-2.0-flash-native-audio-preview. Google iteriert schnell – Updates regelmäßig im Blick behalten.
Architektur und Technologieauswahl
Als Nächstes: Systemaufbau. Empfehlung: Frontend/Backend-Trennung – aus einem klaren Grund: Der API Key darf nicht im Frontend liegen.
Datenfluss im Überblick:
[Browser] --WebSocket--> [Python-Backend-Proxy] --WebSocket--> [Gemini Live API]
| | |
Mikrofon-Aufnahme Relay + Business-Logik KI-Verarbeitung
Lautsprecher-Wiedergabe VAD / Barge-in-Steuerung Audio-GenerierungWarum nicht direkt vom Browser zu Gemini? Technisch möglich – aber der API Key müsste im JavaScript stehen. Jeder mit geöffneten DevTools hätte Ihren Schlüssel. Einmal so gemacht, am nächsten Tag explodierte die Rechnung – bittere Lektion.
Der gewählte Stack:
| Ebene | Technologie | Zweck |
|---|---|---|
| Frontend | Vanilla JavaScript + Web Audio API | Aufnahme, Wiedergabe, AudioWorklet in Echtzeit |
| Backend | Python 3.9+ + websockets | WebSocket-Proxy, VAD, Sitzungsverwaltung |
| Protokoll | WebSocket + JSON | Bidirektionale Kommunikation mit Gemini |
AudioWorklet in der Web Audio API verarbeitet Audio in einem eigenen Thread ohne den Hauptthread zu blockieren. Konkreter Code folgt unten.
WebSocket-Verbindung und Sitzungsverwaltung
Jetzt zum Code: Verbindung zu Gemini herstellen.
WebSocket-Endpunkt der Live API:
wss://generativelanguage.googleapis.com/ws/google.ai.generativelanguage.v1alpha.GenerativeService.BidiGenerateContent?key=YOUR_API_KEYBeachten Sie v1alpha – Preview, Schnittstellen können sich ändern; in Produktion vorsichtig planen.
Nach dem Verbindungsaufbau zuerst eine Setup-Nachricht senden:
import asyncio
import json
import websockets
GEMINI_API_KEY = "your-api-key-here"
GEMINI_WS_URL = (
f"wss://generativelanguage.googleapis.com/ws/"
f"google.ai.generativelanguage.v1alpha.GenerativeService.BidiGenerateContent"
f"?key={GEMINI_API_KEY}"
)
CONFIG = {
"setup": {
"model": "models/gemini-2.0-flash-native-audio-preview",
"generation_config": {
"response_modalities": ["AUDIO"],
"speech_config": {
"voice_config": {
"prebuilt_voice_config": {
"voice_name": "Charon" # optional: Charon, Aoede, etc.
}
}
}
},
"system_instruction": {
"parts": [{"text": "Sie sind ein hilfreicher KI-Assistent und antworten knapp und natürlich."}]
}
}
}
async def connect():
async with websockets.connect(GEMINI_WS_URL) as ws:
# Setup-Konfiguration senden
await ws.send(json.dumps(CONFIG))
# Auf setupComplete warten
response = await ws.recv()
data = json.loads(response)
if "setupComplete" in data:
print("✅ Verbindung steht, Dialog kann starten")
return ws
else:
raise Exception(f"Setup fehlgeschlagen: {data}")Wichtige Parameter:
response_modalities:["AUDIO"]– nur Sprachantwort. Für Text zusätzlich["AUDIO", "TEXT"]voice_name: mehrere Preset-Stimmen;Charonklingt ruhig und klar
Bei Verbindungsabbruch: exponentielles Backoff statt sofortiger Massen-Retries:
async def connect_with_retry(max_retries=5):
for attempt in range(max_retries):
try:
return await connect()
except Exception as e:
wait_time = min(2 ** attempt, 30) # maximal 30 Sekunden
print(f"Verbindung fehlgeschlagen ({e}), Retry in {wait_time}s...")
await asyncio.sleep(wait_time)
raise Exception("Verbindung nach mehreren Versuchen fehlgeschlagen")16-kHz-PCM-Audiostream: Aufnahme und Übertragung
Verbindung steht – woher kommt das Audio und wie wird es gesendet?
Warum 16 kHz? Die Stimme liegt etwa bei 85–255 Hz (Männer tiefer, Frauen höher); nach Nyquist reichen theoretisch 8 kHz. Für Details ist 16 kHz der Sweet Spot – gute Qualität, moderates Datenvolumen. Gemini empfiehlt diese Rate offiziell.
Frontend-Aufnahmecode:
class AudioRecorder {
constructor() {
this.sampleRate = 16000;
this.bufferSize = 1024;
this.audioContext = null;
this.workletNode = null;
this.stream = null;
this.onAudioData = null; // Callback
}
async start() {
// Mikrofon-Berechtigung anfordern
this.stream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: 16000,
channelCount: 1,
echoCancellation: true,
noiseSuppression: true
}
});
// AudioContext mit fester Abtastrate
this.audioContext = new AudioContext({
sampleRate: 16000
});
// AudioWorklet-Processor laden
await this.audioContext.audioWorklet.addModule('pcm-processor.js');
const source = this.audioContext.createMediaStreamSource(this.stream);
this.workletNode = new AudioWorkletNode(this.audioContext, 'pcm-processor');
// Audiodaten verarbeiten
this.workletNode.port.onmessage = (event) => {
const float32Data = event.data;
// In Int16-PCM konvertieren
const int16Data = this.float32ToInt16(float32Data);
// Base64 kodieren und senden
const base64Data = btoa(String.fromCharCode(...new Uint8Array(int16Data.buffer)));
if (this.onAudioData) {
this.onAudioData(base64Data);
}
};
source.connect(this.workletNode);
console.log('🎤 Audioaufnahme gestartet');
}
float32ToInt16(float32Array) {
const int16Array = new Int16Array(float32Array.length);
for (let i = 0; i < float32Array.length; i++) {
// Float32 (-1.0 ~ 1.0) -> Int16 (-32768 ~ 32767)
const s = Math.max(-1, Math.min(1, float32Array[i]));
int16Array[i] = s < 0 ? s * 0x8000 : s * 0x7FFF;
}
return int16Array;
}
stop() {
if (this.workletNode) {
this.workletNode.disconnect();
}
if (this.audioContext) {
this.audioContext.close();
}
if (this.stream) {
this.stream.getTracks().forEach(track => track.stop());
}
console.log('🛑 Audioaufnahme gestoppt');
}
}AudioWorklet braucht eine separate Datei pcm-processor.js:
// pcm-processor.js
class PCMProcessor extends AudioWorkletProcessor {
process(inputs, outputs, parameters) {
const input = inputs[0];
if (input && input[0]) {
// An Hauptthread senden
this.port.postMessage(input[0].slice());
}
return true; // Processor aktiv halten
}
}
registerProcessor('pcm-processor', PCMProcessor);Das Backend leitet an Gemini weiter:
async def send_audio(ws, base64_pcm_data):
"""Audiodaten an Gemini senden"""
message = {
"realtime_input": {
"media_chunks": [{
"mime_type": "audio/pcm;rate=16000",
"data": base64_pcm_data
}]
}
}
await ws.send(json.dumps(message))Fallstrick: Manche Browser ignorieren sampleRate in getUserMedia und liefern 44,1 oder 48 kHz. Sicherer: in AudioContext erneut resamplen oder eine Bibliothek wie audiobuffer-to-wav nutzen.
VAD – Sprachaktivitätserkennung
Ohne Filter würde auch Stille an Gemini gesendet – Bandbreite und Kosten steigen. VAD (Voice Activity Detection) entscheidet, ob jemand spricht; nur dann senden.
Empfehlung: WebRTC VAD von Google – leicht, schnell, solide. Python-Paket webrtcvad:
import webrtcvad
import collections
import numpy as np
class VADProcessor:
def __init__(self, aggressiveness=2, frame_duration_ms=20):
"""
aggressiveness: 0-3, höher = strenger (Sprache leichter als Stille)
frame_duration_ms: 10, 20 oder 30
"""
self.vad = webrtcvad.Vad(aggressiveness)
self.frame_duration_ms = frame_duration_ms
self.sample_rate = 16000
# Ringpuffer zur Glättung
self.ring_buffer = collections.deque(maxlen=30) # 600 ms
self.triggered = False
def process_frame(self, pcm_bytes):
"""
Ein Frame verarbeiten; Rückgabe, ob gesendet werden soll
"""
is_speech = self.vad.is_speech(pcm_bytes, self.sample_rate)
if not self.triggered:
# Noch nicht ausgelöst: Sprachframes sammeln
self.ring_buffer.append((pcm_bytes, is_speech))
num_voiced = sum(1 for _, speech in self.ring_buffer if speech)
# 90 % Sprache → auslösen
if num_voiced > 0.9 * self.ring_buffer.maxlen:
self.triggered = True
# Puffer mit senden
return b''.join([f for f, _ in self.ring_buffer])
return None
else:
# Ausgelöst
if is_speech:
self.ring_buffer.append((pcm_bytes, True))
return pcm_bytes
else:
self.ring_buffer.append((pcm_bytes, False))
num_unvoiced = sum(1 for _, speech in self.ring_buffer if not speech)
# 90 % Stille → Auslösung beenden
if num_unvoiced > 0.9 * self.ring_buffer.maxlen:
self.triggered = False
self.ring_buffer.clear()
return pcm_bytesTypische Nutzung:
vad = VADProcessor(aggressiveness=2)
async def handle_client_audio(websocket, gemini_ws):
async for message in websocket:
data = json.loads(message)
if 'audio' in data:
pcm_bytes = base64.b64decode(data['audio'])
# VAD
result = vad.process_frame(pcm_bytes)
if result:
# Sprache erkannt → an Gemini
await send_audio(gemini_ws, base64.b64encode(result).decode())aggressiveness ist fein: zu niedrig → Hintergrund als Sprache; zu hoch → leises Sprechen wird übersehen. Start mit 2, dann anpassen.
Ohne webrtcvad im Backend: einfache Energie-Schwelle im Frontend:
// Fallback: einfache Erkennung über RMS-Energie
function detectVoiceActivity(audioData, threshold = 0.015) {
const sum = audioData.reduce((acc, val) => acc + val * val, 0);
const rms = Math.sqrt(sum / audioData.length);
return rms > threshold;
}Barge-in – natürliches Unterbrechen
Bei manchen Sprachassistenten müssen Sie warten, bis die KI fertig ist – frustrierend.
Barge-in erlaubt Unterbrechung während der KI-Antwort; die Ausgabe stoppt, der Nutzer kann sofort weitersprechen.
Gemini Live API unterstützt das nativ. In der Konfiguration automatische Aktivitätserkennung aktivieren:
CONFIG = {
"setup": {
"model": "models/gemini-2.0-flash-native-audio-preview",
"generation_config": {
"response_modalities": ["AUDIO"],
},
"realtime_input_config": {
"automatic_activity_detection": {
"disabled": False,
"start_of_speech_sensitivity": "START_SENSITIVITY_HIGH",
"end_of_speech_sensitivity": "END_SENSITIVITY_LOW"
}
}
}
}Zu sensitivity:
start_of_speech_sensitivity:HIGH– empfindlicher für Sprechbeginn, leichteres Unterbrechenend_of_speech_sensitivity:LOW– wartet länger, bis der Nutzer wirklich fertig ist
Clientseitig auf interrupted hören und Wiedergabe stoppen:
class GeminiClient {
constructor() {
this.audioQueue = [];
this.isPlaying = false;
this.currentSource = null;
}
async handleMessage(event) {
const message = JSON.parse(event.data);
// Unterbrechungssignal
if (message.server_content?.interrupted) {
console.log('⚡ Nutzer unterbricht – Wiedergabe stoppen');
this.stopPlayback();
return;
}
// KI-Audio verarbeiten
if (message.server_content?.model_turn) {
const parts = message.server_content.model_turn.parts;
for (const part of parts) {
if (part.inline_data?.mime_type.startsWith('audio/')) {
const audioData = base64ToArrayBuffer(part.inline_data.data);
this.queueAudio(audioData);
}
}
}
}
stopPlayback() {
// Warteschlange leeren
this.audioQueue = [];
this.isPlaying = false;
// Laufende Wiedergabe stoppen
if (this.currentSource) {
try {
this.currentSource.stop();
} catch (e) {
// bereits gestoppt
}
this.currentSource = null;
}
}
async queueAudio(audioData) {
this.audioQueue.push(audioData);
if (!this.isPlaying) {
this.playNext();
}
}
async playNext() {
if (this.audioQueue.length === 0) {
this.isPlaying = false;
return;
}
this.isPlaying = true;
const audioData = this.audioQueue.shift();
// Dekodieren und abspielen
const audioBuffer = await this.audioContext.decodeAudioData(audioData.slice());
this.currentSource = this.audioContext.createBufferSource();
this.currentSource.buffer = audioBuffer;
this.currentSource.connect(this.audioContext.destination);
this.currentSource.onended = () => {
this.playNext();
};
this.currentSource.start();
}
}Detail: stop() kann werfen, wenn das Audio schon zu Ende ist – daher try-catch.
Performance und Latenzkontrolle
Woher kommt Latenz?
- Netzwerk: Roundtrip Browser → Server → Gemini
- Audio-Codec: PCM ist verlustfrei, Overhead gering
- Puffer: Tiefe für flüssige Wiedergabe
Optimierungen:
Geringe Puffertiefe
100–200 ms reichen oft:
// Kleiner Puffer
const audioContext = new AudioContext({
sampleRate: 16000,
latencyHint: 'interactive' // Low-Latency-Modus
});Adaptiver Puffer
Bei Netzwerk-Jitter etwas mehr Puffer; bei stabiler Verbindung reduzieren.
Echo-Unterdrückung lokal
Mit Lautsprecher statt Headset nimmt das Mikrofon die KI-Stimme auf. getUserMedia bietet Echo Cancellation:
navigator.mediaDevices.getUserMedia({
audio: {
echoCancellation: true,
noiseSuppression: true,
autoGainControl: true
}
})Metriken
Performance API zum Messen:
// Latenz messen
class LatencyMonitor {
constructor() {
this.metrics = [];
}
recordSendTime() {
this.lastSendTime = performance.now();
}
recordReceiveTime() {
const latency = performance.now() - this.lastSendTime;
this.metrics.push(latency);
// letzte 100 Einträge
if (this.metrics.length > 100) {
this.metrics.shift();
}
const avg = this.metrics.reduce((a, b) => a + b, 0) / this.metrics.length;
console.log(`📊 Durchschnittliche Latenz: ${avg.toFixed(2)}ms`);
}
}Typische Testwerte:
- End-to-End: 300–500 ms (netzabhängig)
- Time-to-first-byte: 200–400 ms
- Fortlaufender Dialog: 150–300 ms
Deutlich höhere Werte? Checkliste:
- WebSocket über WSS? HTTP erzeugt Extra-Overhead
- Server-Standort nah an Google-Rechenzentren?
- VAD zu träge? Kürzere Frame-Dauer testen
- Frontend-Puffer zu groß?
Chrome verlangt User-Gesture vor Audio – Button „Dialog starten“ einplanen, nicht sofort autoplay.
Fazit
Damit ist der Weg von der Gemini Live API bis zur lauffähigen App durchgespielt: Konzept, Architektur, WebSocket, Audioaufnahme, VAD, Barge-in und Latenzoptimierung – inklusive der Fallstricke aus der Praxis.
Echtzeit-Sprache entwickelt sich schnell; Gemini Live API wird weiter aktualisiert. Diese Basisarchitektur hält sich dennoch – in meinem Projekt seit Monaten stabil.
Bei Fragen in der Entwicklung: gern austauschen. Gemeinsam geht es meist schneller als allein.
FAQ
Warum ist eine Frontend/Backend-Trennung zwingend?
Warum 16 kHz Abtastrate?
Wie stellt man den VAD-aggressiveness-Parameter ein?
Muss Barge-in extra entwickelt werden?
8 Min. Lesezeit · Veröffentlicht am: 27. Feb. 2026 · Aktualisiert am: 20. Juni 2026
Google AI Mastery
Du liest den ersten Beitrag dieser Serie. Lies den nächsten Beitrag oder öffne die Serienübersicht, um den gesamten Pfad zu sehen.
Vorheriger
Du bist am Anfang dieser Serie.
Nächster
Vektordatenbank ade? Gemini 2M Token Langkontext & Context Caching – Performance- und Kostenvergleich
Tiefgehender Test von Geminis Langkontext und Context Caching im Vergleich zu klassischem RAG – für fundierte Architekturentscheidungen
Teil 2 von 7
Ähnliche Beiträge
NotebookLM in der Praxis: Wie Sie 400 Forschungsquellen in ein interaktives „Digitales Gehirn“ verwandeln

NotebookLM in der Praxis: Wie Sie 400 Forschungsquellen in ein interaktives „Digitales Gehirn“ verwandeln
Ein Blick in die Seele der KI: Code-Logik mit Gemini 3.1 Chain-of-Thought-Leaks debuggen

Ein Blick in die Seele der KI: Code-Logik mit Gemini 3.1 Chain-of-Thought-Leaks debuggen
AI SEO in der Praxis: Mit NotebookLM und Gemini 3 zur Content-Factory

Kommentare
Melde dich mit GitHub an, um einen Kommentar zu hinterlassen